[Pandas] 같은 범주로 묶기(groupby)
- Python / Pandas
- 2021. 5. 6.
groupby() 함수를 이용해 데이터프레임을 범주별로 묶어 통계내고 범주별로 출력하는 방법을 소개하겠습니다.
엑셀에서 흔히 쓰는 필터링 역할을 groupby()를 통해 할 수 있는데 한 눈에 볼 수 없다는 단점은 있지만
groupby로 손쉽게 묶어낼 수 있고 빠르게 데이터 처리를 할 수 있기 때문에 유용하게 사용됩니다.
예제 자료는 랜덤으로 (9,4)을 만들어서 넣었습니다. 인덱스는 시간데이터로 하였습니다.
랜덤으로 만들고 시간데이터를 만드는 방법은 이미 포스팅을 해놨으니 관련 포스팅을 참고해주시기 바랍니다.
df
9개의 행으로 이루어진 데이터프레임입니다.
df를 3개씩으로 범주를 넣어 구분하겠습니다.
df['Quarter'] = ['Q1','Q1','Q1','Q2','Q2','Q2','Q3','Q3','Q3']
df'Quarter' 로 간단하게 순서대로 3개씩 구분하였습니다.
이제 groupby()를 이용해서 'Quarter'를 기준으로 범주를 나눕니다.
괄호 안에 원하는 범주로 쓸 column의 이름을 입력합니다.
groups = df.groupby('Quarter')
group.size()
통계
이 범주를 기준으로 column별로 통계를 내보겠습니다.
groups.mean() #평균
groups.max() #최대값
groups.aggregate([min,max]) #min, max 함께 출력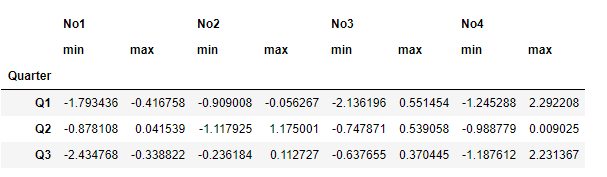
groups.aggregate(['mean','std']) # 평균, 표준편차 함께 출력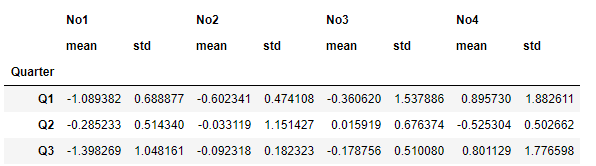
groups.describes() # 통계 모두 출력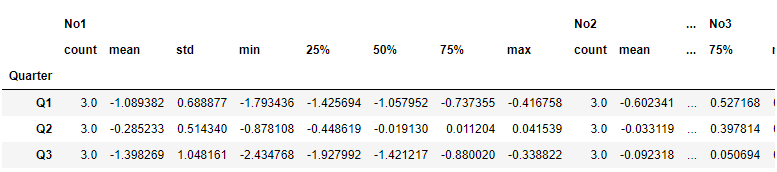
두개 이상의 column으로 그룹화
두개이상의 column을 기준으로 그룹화도 가능합니다.
인덱스의 월을 기준으로 홀수,짝수로 나누겠습니다.
멋있게 할 수 있지만 그건 관련 포스팅을 참고해 주시기 바랍니다.
df['Month odd_even'] = ['Odd','Even','Odd','Even','Odd','Even','Odd','Even','Odd']
df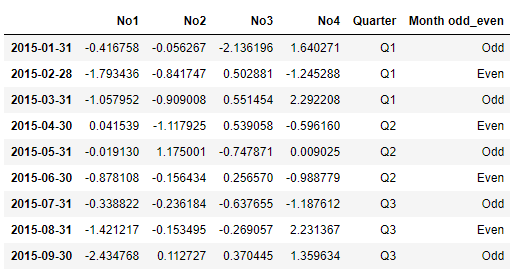
groups_two = df.groupby(['Quarter','Month odd_even'])
groups_two.size()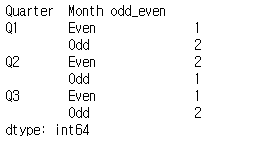
'Quarter' 와 'Month odd_even으로 범주를 나누었습니다.
범주별 출력(딕셔너리로 만들기)
마지막으로 범주별로 묶인 딕셔너리를 만들고 포스팅을 마치겠습니다.
사실, 범주별로 나누기만 한다면 groupby를 굳이 안하고 판다스에서 바로 출력할 수 있습니다.
df[df['Quarter']=='Q1']
위의 코딩은 당장 간편한 것 같지만 반복문을 통해 데이터프레임을 나누어야 하고 메모리를 생각하면 많은 양을 할 수가 없습니다. 이럴 경우 범주로 나누면서도 메모리 용량을 아끼기 위해 딕셔너리로 범주별로 저장합니다.
딕셔너리로 바꾸면 for를 쓸 이유가 없습니다.
코드 한 줄이면 분류가 됩니다.
groupby를 쓴다면 다음과 같이 간편하게 할 수 있습니다.
result = dict(list(groups)) #딕셔너리로 범주별로 저장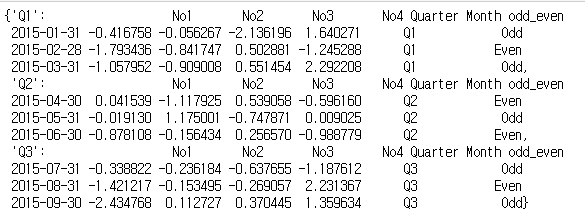
'Quarter'를 기준으로 groupby를 한 결과를 리스트에서 넣고 다시 딕셔너리로 넣으면 끝이 납니다.
한개씩 뽑으면 위와 같이 bool을 이용한 방법과 같은 데이터프레임을 구할 수 있습니다.
result['Q1']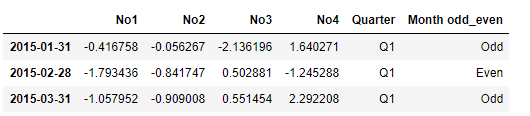
데이터프레임 그대로 딕셔너리에 저장되는걸 확인할 수 있습니다.
관련포스팅
[Python/Numpy] - ndarray 랜덤한값 생성
'Python > Pandas' 카테고리의 다른 글
| [Pandas]데이터프레임 합치기(join) (0) | 2021.05.08 |
|---|---|
| [Pandas] 데이터프레임 합치기(append,concat) (0) | 2021.05.07 |
| [Pandas] 시간데이터 만들기(date_range) (0) | 2021.05.03 |
| [Pandas] 데이터프레임 엑셀(xlsx) 저장, 불러오기 (0) | 2021.04.17 |
| [Pandas] 원하는 값으로 필터링 (0) | 2021.04.11 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!