[Pandas] CSV 저장,불러오기
- Python / Pandas
- 2022. 1. 19.
이번 포스팅은 판다스로 CSV 파일 저장, 불러오는 방법입니다.
CSV(comma-separated values)는 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일로 이루어져 있습니다.
데이터를 간편하게 저장하기에 용이해서 데이터 전처리 작업을 하게 되면 한번쯤은 다루게 되는 파일형식입니다.
CSV 저장하기
데이터프레임 작업을 마치고 CSV로 저장하는 방법입니다.
아래 코드처럼 경로에 파일이름 만들어서 저장합니다.
예를 들어, apple 이라는 파일이름을 지정하고 싶다면 '경로/apple.csv' 를 경로에 넣으시면 됩니다.
기존에 있던 파일이름이 있다면 덮어쓰기가 되니 주의하셔야 합니다.
데이터프레임의 index 설정이 안되어 있으면 숫자로 인덱스가 붙여진 것을 볼 수 있습니다.

이 상태에서 저장을 하면 엑셀의 좌표(0,0)에는 아무 글자가 안 쓰여 있게 됩니다.
이렇게 저장한 데이터를 불러오게 되면 이름이 지정이 안 된 컬럼이름이 unnamed:0 와 같은 형식으로 붙어서 불러와집니다. unnamed:0 을 없애야 하는 상황이 발생하게 되어서 애를 먹게 됩니다.
index_label을 붙여서 저장하는 습관을 가지고 있는게 좋습니다.
따라서 저장을 할때는 다음과 같이 하는 것을 추천합니다.
apple.to_csv('경로', index_label='date')만약 인덱스를 따로 설정하지 않았고 unnamed:0을 방지하고 싶다면 index=False를 추가합니다.
index = False를 하면 csv에 맨 앞에 번호를 적어놓는 컬럼이 생기지 않고 저장이 됩니다.
apple.to_csv('경로',index=False)
CSV 불러오기
애플의 2018년부터의 가격데이터를 불러오겠습니다.
apple = pd.read_csv('경로')경로란에 불러오고자 하는 csv 경로를 넣으시면 됩니다.
잘 불렀다면 아래오 같이 데이터프레임이 나오게 됩니다.
아무 설정없이 불러오면 앞에 인덱스가 붙여지게 됩니다.
이를 없애고 싶다면 다음과 같이 index_col=0 을 입력합니다.
0번째 컬럼을 인덱스로 설정하겠다는 얘기입니다.
apple = pd.read_csv('경로',index_col=0)
csv를 불러오는데에 다양한 기능이 있는데요.
많이 쓸만한 몇가지를 소개하겠습니다.
먼저 컬럼명을 바꿀 수 있습니다.
컬럼명을 모두 소문자로 바꾸겠습니다.
apple = pd.read_csv('경로',names=['open','high','low','close','volume','adjclose'])
원래 있던 컬럼이름이 밑으로 내려가는 걸 볼 수 있는데 이를 없애기 위해 header=0 도 같이 씁니다.
apple = pd.read_csv('경로',names=['open','high','low','close','volume','adjclose'],header=0)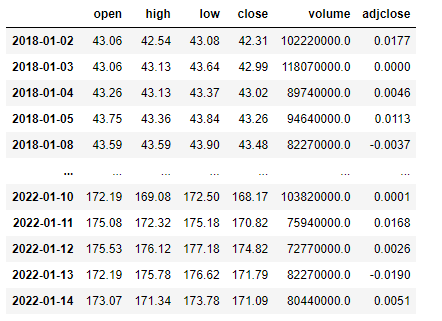
원하는 컬럼을 가지고 오고 싶다면 usecols을 씁니다.
apple = pd.read_csv('경로',usecols=['Date','Close'])
인덱스를 지정하고 싶은 컬럼을 미리 설정할 수 있는데 index_col 로 지정합니다.
apple = pd.read_csv('경로',usecols=['Date','Close'],index_col=['Date'])
메모리 절약을 위해 필요한 행만 가져오고 싶다면 nrows를 사용합니다.
pd.read_csv('경로',nrows=3)

정제되지 않는 csv 불러오기
웹크롤링을 하거나 여러가지 파일을 웹에서 받게 되면 정제되지 않는 csv 파일을 보게 됩니다.
csv파일이 컴마(,) 에 의해 구분되어 있거나 | 으로 구분되어 있는 경우가 있습니다.
이런 경우에도 판다스로 컬럼이 구분되게끔 불러올 수 있습니다.
csv 파일을 열어보았더니 다음과 같이 나왔다고 합시다.

| 으로 구분되어있는 걸 확인할 수 있습니다.
이 파일을 데이터프레임으로 불러오고 싶다면 다음과 같이 코드를 작성합니다.
둘 중에 아무거나 해도 같은 결과가 나옵니다.
pd.read_csv('경로',sep='|') # pd.read_table('경로',sep='|')

| 구분에 따라 데이터프레임이 잘 구분되어서 나오는 것을 볼 수 있습니다.
컴마로 분류되어 있다면 sep=',' 을 씁니다.
pd.read_csv('경로',sep=',') # pd.read_table('경로',sep=',')
불필요한 행 빼기
종종 데이터 불필요한 내용이 있을 때가 있습니다.
아래 그림처럼 첫번째 줄은 필요가 없는 내용입니다.
이를 빼고 불러올 수 있습니다. 거기에 더하여 자신이 빼고 싶은 행이 있다면 다같이 뺄 수 있습니다.
첫번째 줄과 4번째 줄을 없애보겠습니다.
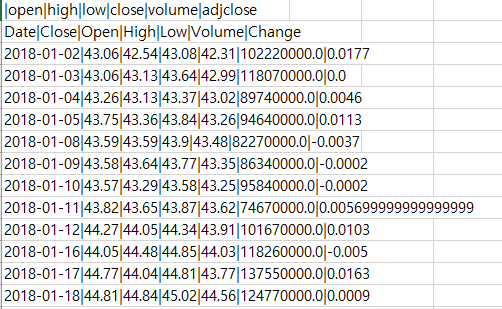
pd.read_csv('경로',skiprows=[0,3],sep='|')
2018-01-03 이 빠진 상태로 불러온 것을 볼 수 있습니다.
마치며
판다스가 생각보다 많은 파일형식을 불러올 수 있습니다.
형식도 굉장히 비슷하기 때문에 한번만 이해가 된다면 다른 파일형식도 쉽게 열 수 있을겁니다.
csv인 경우 공공데이터와 같이 한글을 쓰는 경우 인코딩 문제가 발생할 수 있습니다. 인코딩 문제에 대한 해결책은 아래에 링크에서 살펴보실 수 있습니다.
관련 포스팅
[Python/기초] - [Pandas] csv 한글 깨짐 문제해결
'Python > Pandas' 카테고리의 다른 글
| [Pandas] SQL 데이터베이스 저장, 불러오기 (0) | 2022.01.31 |
|---|---|
| [Pandas] replace로 값 변경하기 (0) | 2022.01.28 |
| [Pandas] 원하는 위치값 가져오기(at,iat) (0) | 2022.01.14 |
| [Pandas] series 인덱스로 값 찾기 (0) | 2022.01.10 |
| [Pandas] 빈 데이터프레임 만들기 (0) | 2021.12.29 |



