[Pandas] 데이터프레임 리스트,numpy 배열로 변환
- Python / Pandas
- 2022. 9. 22.
데이터 프레임을 리스트로 변환하는 방법입니다.
데이터 프레임도 굳이 리스트로 바꾸는 이유는 머신러닝이나 딮러닝을 할 때 리스트로 input 값을 넣어야 할 때가 있습니다. 근데 데이터 전처리는 판다스가 훨씬 효과적이기 때문에 전처리 후 리스트 형태로 바꾸어 input값으로 쓸 수 있습니다.
데이터프레임에서 column별로 가져오면 되지 않느냐?라고 반문할 수도 있지만 머신러닝이나 딮러닝 처리중 계산 때문에 불가할 수 있고 여러 클래스인경우 벡터화해서 계산하는 것이 훨씬 빠르기 때문에 ndarray로 바꾸는 게 용이합니다.
데이터프레임에서 리스트와 numpy 배열로 변환하는 방법을 알려드리겠습니다.
데이터는 머신러닝 연습용으로 많이 쓰는 꽃 분석 데이터인 iris로 하겠습니다.
import pandas as pd
from sklearn import datasets
iris = dataset.load_iris()
df = pd.DataFrame(iris['data'],columns=iris['feature_names'])
딕셔너리 형태로 만들어서 리스트로 변환
조금 복잡하지만 딕셔너리에서 하나씩 뽑아쓰는 형식이 될 수 있으므로 for문을 돌려야한다면 메모리를 많이 차지하는 데이터프레임보다는 딕셔너리로 바꾸어서 리스트로 변환하는 방법으로 쓸 수 있습니다. 기본적으로 컬럼별로 딕셔너리가 생성되니 컬럼별로 뽑아서 리스트로 변환해주면 됩니다.
df_dict = df.to_dict()
col_list = list(df_dict[df.columns[0]].values())
딕셔너리로 바꾸는 방식은 여러가지가 있습니다.
지금은 리스트에 대해 쓰고 있으니 자세한 사항은 아래 포스팅에서 살펴보시면 되겠습니다.
[Pandas] DataFrame을 딕셔너리로 변환
DataFrame을 딕셔너리로 변환하는 방법에 대해 알아보겠습니다. to_dict 을 이용해 할 수 있는데 경우의 수가 좀 있어서 다양하게 딕셔너리를 만들 수 있습니다. 매개변수도 존재하는데 list, records, se
seong6496.tistory.com
특정 컬럼 선택 후 리스트 변환
컬럼을 선택한 후 리스트를 변환합니다. 필요한 것만 가져올 수 있어서 데이터프레임으로 구성된 모든 데이터가 필요없을 때 쓰는 방법입니다. 특히, 머신러닝에서는 target 값으로 가져올 때 편합니다.
df[df.columns[0]].to_list()
# or
df[df['컬럼명']].to_list()행(row)별로 리스트 변환
인덱스별로 리스트를 가져올 때는 iloc나 loc를 이용하여 리스트로 변환합니다.
iloc나 loc를 모르시는 분들은 아래 포스팅을 참고하시기 바랍니다.
[Pandas] DataFrame 특정 row 선택하는 두가지 방법(loc,iloc)
이번 포스팅에서는 DataFrame 에서 row를 선택하는 방법에 대해 살펴볼까 합니다. 크게 두가지 방법이 있는데요. 둘 다 인덱스를 사용하는 것은 같지만 DataFrame 에서 사용하는 인덱스를 우리가 설정
seong6496.tistory.com
#iloc
df.iloc[0].to_list()
#loc
df.loc[0].to_list()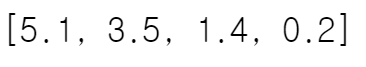
numpy 배열로 변환(ndarray)
데이터프레임의 모든 데이터를 한꺼번에 리스트로 변환하는 건 현재 불가능합니다. 보통 계산을 위해 전체변환을 하는 것이라 numpy가 훨씬 효율적이고 계산도 빠르기 때문에 없는게 아닐까 싶습니다. numpy로 바꾸는 건 굉장히 간단합니다. to_numpy()을 사용하기만 하면 됩니다.
df.to_numpy()
응용
여러가지 응용이 가능한데 컬럼 선택해서 numpy로 만드는 방법과 True, False를 이용해서 분별후 numpy로 만드는 방법을 보여드리겠습니다.
# column 두개 선택후 numpy 변환
df[[df.columns[0],df.columns[1]]].to_numpy()
이번엔 5보다 큰 숫자만 가져온 후 numpy로 변환해보겠습니다.
boolean 처리를 하는 경우에는 False 값은 nan으로 처리됩니다. nan을 다른 값으로 바꾼 후 numpy로 변환하시면 됩니다.
df[df>5].fillna(0).to_numpy()nan(결측치) 처리는 여러가지방법이 있는데 이에 대한 자세한 사항은 아래 포스팅을 참고해주시기 바랍니다.
[Pandas] DataFrame 결측치(NaN) 처리
데이터를 수집하면 전산오류나 사람의 실수로 결측치가 발생하게 됩니다. 특히 외부에서 데이터를 가져오면 더욱 그럴 수 밖에 없는데 결측치를 방치하고 알고리즘에 데이터셋을 넣게 되면 아
seong6496.tistory.com
마치며
리스트로 변환하는 방법에 대해 알려드렸습니다.
잘 활용하셔서 간편하게 코딩 작업하시기 바랍니다.
관련 포스팅
[Pandas]DataFrame column 추가,삭제,순서변경
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 순위 구하기(rank) (0) | 2022.11.21 |
|---|---|
| pandas cheatsheet(코드요약) (0) | 2022.09.24 |
| pandas로 box,area,scatter 그리기 (0) | 2022.03.17 |
| pandas로 bar,hist,density 그리기 (0) | 2022.03.15 |
| pandas plot (0) | 2022.03.10 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!