세상 간단한 R로 웹 스크래핑하기
- R
- 2024. 7. 24.
R로 웹 스크래핑하기
R을 사용해 웹 스크래핑을 하려면 rvest라는 패키지를 사용합니다. rvest는 HTML 문서를 파싱하고 데이터를 추출하는 패키지로 간편하게 웹 스크래핑을 할 수 있습니다.
R을 활용한 간단한 웹 스크래핑을 단계별로 보여드리겠습니다.
1. 패키지 설치 및 로드
R은 패키지 설치가 잘 안될 수도 있는데 혹시 패키지 설치가 잘 안된다면 아래 포스팅에서 해결을 해보시기 바랍니다.
R studio 패키지 설치 오류 모음
R은 패키지 설치가 너무 어렵다R은 깔끔하게 코드를 작성할 수 있어 좋은데 호환성이 너무 안좋습니다. 조금만 엇나가면 바로 안됩니다. 힘드네요. 특히 패키지 설치로 애를 아주 많이 먹었습니
seong6496.tistory.com
rvest를 설치한후 불러옵니다.
install.packages("rvest")
library(rvest)2. 웹 페이지 읽기
웹 스크래핑할 URL을 지정하고 read_html()을 이용해 웹 페이지를 불러옵니다.
url <- "https://example.com"
webpage <- read_html(url)3. HTML 요소 추출
html_nodes()와 html_text() 함수를 사용하여 원하는 HTML 요소를 추출합니다.
# 특정 클래스의 모든 요소 추출
nodes <- html_nodes(webpage, ".specific-class")
# 텍스트 추출
text <- html_text(nodes)4. 데이터 프레임에 저장
추출한 데이터를 데이터 프레임에 저장합니다.
data <- data.frame(text = text)
rvest 로드 -> URL 지정 -> html 요소 추출 -> 데이터 저장.
4단계로 웹 스크래핑을 완성합니다. 굉장히 간단하죠?
이 방식으로 네이버 뉴스 제목을 스크래핑해보겠습니다.
먼저 네이버 뉴스에서 뉴스 제목이 나올만한 곳을 찾아가서 html 구조를 살펴야합니다.
네이버 뉴스의 경제면을 보면 뉴스제목이 나열되어있는데 개발자 모드로 해서 뉴스 제목이 어떤 클래스로 이루어져 있는지 살펴봅니다.


strong class ="sa_text_strong"으로 되어있네요.
필요한 내용을 봤으니 이제 추출을 해봅시다.
# 필요한 패키지 로드
library(rvest)
# URL 지정 (네이버 뉴스 경제 메인 페이지)
url <- "https://news.naver.com/section/101"
# 웹 페이지 읽기
webpage <- read_html(url)
# html 요소 추출
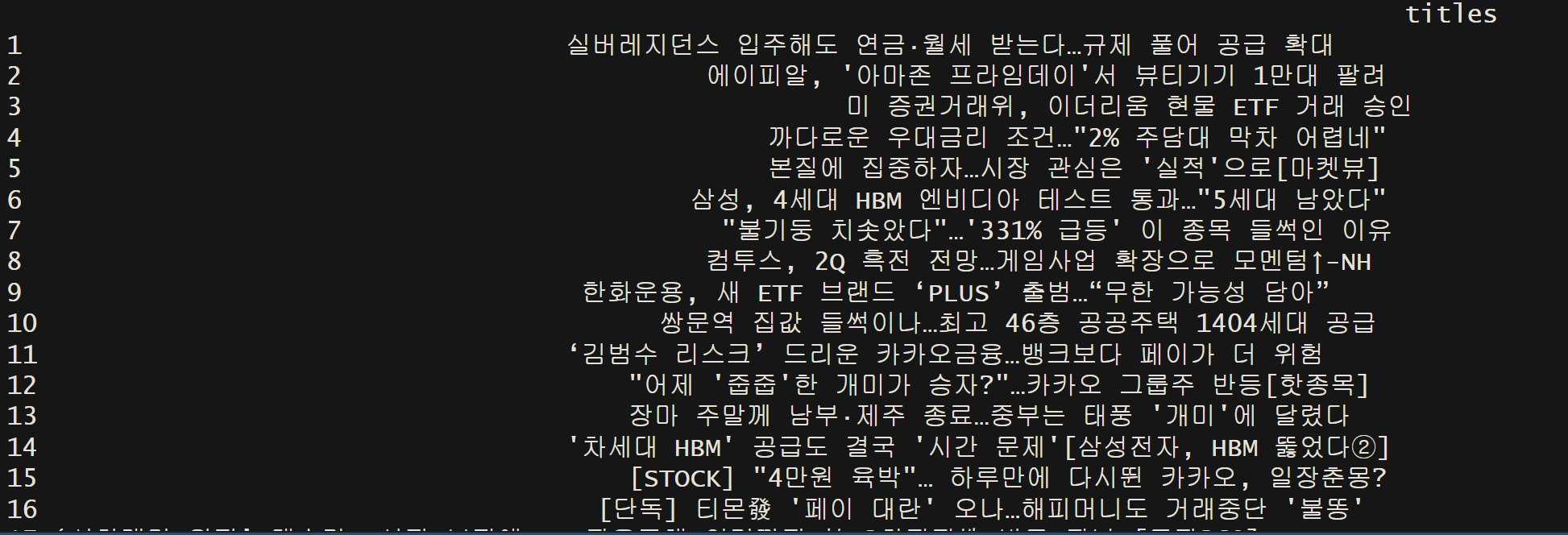
titles <- webpage %>%
html_nodes("strong.sa_text_strong") %>% # 'sa_text_strong' 클래스를 가진 'strong' 태그 선택
html_text(trim = TRUE) # 텍스트 추출 및 공백 제거
# 데이터 프레임에 저장
news_data <- data.frame(titles = titles)
# 결과 출력
print(news_data)

마치며
html 구조만 안다면 간단하게 웹 스크래핑을 할 수 있습니다. 다만, 참고할 것은 일부 웹 사이트는 자바 스크립트로 되어있어 동적 콘텐츠로서 로드합니다. 이런 경우는 rvest에서는 하지 못합니다. 자바 스크립트 웹 스크래핑을 하기 위해선 RSelenium을 이용합니다. 추후에 RSelenium에 대해 글을 쓰겠습니다. 그럼 이만!
'R' 카테고리의 다른 글
| R로 데이터 불러오기와 저장하기 (0) | 2024.07.26 |
|---|---|
| R로 ROC 곡선 분석하기 (0) | 2024.07.25 |
| R studio 패키지 설치 오류 모음 (0) | 2024.07.20 |
| R을 활용한 독립표본 t검정하기 (2) | 2024.07.18 |
| R을 이용한 대응표본 t-검정하기 (0) | 2024.07.15 |



