[Pandas] DataFrame 살펴보기(생성,데이터파악)
- Python / Pandas
- 2020. 7. 6.
DataFrame에 대해 살펴보겠습니다.
Series가 1차원 형태의 자료구조라면 DataFrame은 2차원 형태의 자료구조입니다.
Series보다 훨씬 다양하게 쓸수 있고 흔히 쓰는 엑셀(Excel)의 스프레트시트와 형태가 비슷하기 때문에
사용법을 조금 익히시면 계산측면에서는 엑셀보다 훨씬 효율적으로 쓸 수 있을겁니다.
DataFrame 생성하기
먼저 DataFrame을 생성해서 살펴보겠습니다.
from pandas import Series, DataFrame
raw_data = {'col0':[1,2,3,4],'col1':[10,20,30,40],'col2':[100,200,300,400]}
data = DataFrame(raw_data)
print(raw_data)
raw_data를 보시면 일반적인 딕셔너리입니다. 이렇게 딕셔너리로 이루어진 어떤 데이터가 있다면 이 데이터를 DataFrame처럼 만들어 달라는 요청을 하면 DataFrame 틀에 맞게 모양이 바뀝니다.
(DataFrame을 import 했기 때문에 pandas.DataFrame(raw_data)로 하지 않았습니다.)
print(data)엑셀에서 보던 row와 column이 존재하는 데이터로 바뀐것을 볼 수 있습니다. 이것이 바로 DataFrame입니다.
각 row 인덱스 데이터 추출은 Series에서 해봤기 때문에 column을 해보겠습니다.
data['col1']간단한 방법으로 할 수 있습니다.
리스트 다루듯이 col1인덱스로 이루어진 데이터를 가져올 수 있습니다.
보시는 바와 같이 data['col1']은 Series와 같은 모양임을 알 수 있습니다.
실제로도 타입이 Series입니다.
type(data['col1'])따라서 DateFrame은 Series의 확장된 버젼임을 알 수 있습니다. 즉, 1차원의 Series를 가지고 2차원의 DataFrame을 이루게 된 것입니다. 느낌이 오시겠지만 Series에서 하던 연산이나 슬라이싱이나 DataFrame에서 다 할 수 있습니다.
또한, col1의 0번째같이 값 하나도 선택할수 있습니다.
예전에 파이썬으로 데이터를 다루었던 방식으로 data['col1'][0]을 하면 값을 하나씩 골라낼 수 있습니다.
data['col1'][0]
DataFrame 데이터 파악
DataFrame의 가장 큰 장점은 데이터 파악이 쉽다는 것입니다.
describe 함수를 이용하면 column별로 count, mean, std, min, max를 한눈에 볼 수 있습니다.
data.describe()
info() 함수를 이용하면 데이터의 전체적인 정보도 볼 수 있습니다.
data.info()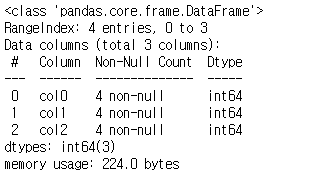
info 함수를 이용하면 위와 같이 column의 이름이나 각 column의 원소갯수, dtype을 한눈에 볼 수 있습니다.
DataFrame의 형태를 보고싶다면 Series와 같이 shape를 이용하면 됩니다.
data.shape
이상으로 포스팅을 마치겠습니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] DataFrame 인덱스 설정, 리셋 (0) | 2020.12.05 |
|---|---|
| [Pandas]DataFrame column 추가,삭제,순서변경 (0) | 2020.07.16 |
| [Pandas]Series 슬라이싱 (0) | 2020.07.01 |
| [Pandas]Series drop, dropna (0) | 2020.06.28 |
| Series Boolean Select (0) | 2020.06.24 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!