[Pandas] 중복데이터 병합하기(column이 모두 같은 경우)
- Python / Pandas
- 2021. 12. 3.
데이터 프레임을 병합하는 과정에서 중복한 데이터를 빼고 병합하고 싶은 경우가 생길 수 있습니다.
merge, concat, join도 병합 메쏘드 중에 하나인데
중복이 있고 column이 똑같은 데이터프레임의 병합에서는 문제가 발생할 수 있습니다.
이는 각각의 메쏘드의 특징이 달라서인데요.
merge는 서로 다른 column일 때 합치기 편하고 concat과 append는 row를 하나씩 추가하는 방식입니다.
join은 인덱스를 기준으로 column으로 합쳐나가는 방식입니다.
만약 데이터프레임 A와 B의 column은 같은데 중복데이터만 없애고 합치고 싶다면 모든 메쏘드가 적절하지 않을 수 있습니다.
왜냐하면 key가 중복된 상황에서 merge를 하게 되면 merge는 key에서 가능한 모든 경우의 수를 생각해 column과 row에 추가하므로 데이터프레임은 몇 배로 커지고 다른 중복을 낳을 수 있기 때문이죠.
concat, append, join은 추가만 되기 때문에 merge보다는 상황이 괜찮습니다만 빅데이터로 넘어가게 되면 사실상 찾을 수 없습니다.
다행히도 판다스에 중복데이터의 존재를 알아보고 제거할 수 있는 메쏘드가 있습니다.
바로 중복데이터의 존재를 알 수 있는 duplicated()와 중복데이터를 제거를 할 수 있는 drop_duplicates()입니다.
이를 이용해 데이터 전처리를 하면 깔끔하게 중복데이터를 없앨 수 있습니다.
중복데이터 존재 확인(duplicated())
duplicated()는 중복 데이터 여부를 boolean으로 출력합니다.
예에 duplicated()를 바로 적용해보겠습니다.
df = pd.DataFrame(dict(level=[1,2,3,3,5,6],age=[12,20,20,20,21,23]))
df
level column에서는 3이 똑같고 age에서는 20이 똑같습니다.
인덱스 2와 3은 전부 똑같습니다.
이를 duplicated() 메쏘드를 쓰면 boolean으로 볼 수 있습니다.
각 column 이름을 key값에 적용하면 됩니다.
여러개도 가능하기 때문에 리스트 형태로 파라미터를 작성합니다.
df.duplicated(['level']) # level 기준으로 중복 데이터 여부 출력df.duplicated(['level','age']) # 두개 이상도 가능
타입이 bool이면 데이터프레임내에서 필터링이 가능하므로 중복된 값만 따로 볼 수 있습니다.
df[df.duplicated(['level','age'])==True]
중복데이터 제거(drop_duplicates())
중복데이터를 없애달라고 요구할 수 있습니다.
위 예제를 가져와서 실행해보면 다음과 같이 나옵니다.
df.drop_duplicates(['level','age'])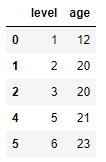
중복데이터인 인덱스 3이 없어진 걸 확인할 수 있습니다.
응용
시계열 데이터를 다룰 때 중복 데이터가 많을 수 있는데 한번 병합을 해보겠습니다.
요즘 가상화폐가 핫하니 비트코인의 틱데이터로 예를 들겠습니다.
이런 경우가 발생합니다.
업비트에서 틱데이터를 가져올 수 있는데 업비트에서는 한 번에 500개의 데이터만 받을 수 있습니다.
이를 연속해서 받게 되면 시간이 겹칠 수 밖에 없습니다.
틱은 거래 체결을 기준으로 데이터가 생겨나기 때문에 같은 시간에 여러개의 데이터가 있을 수 있습니다.
그래서 시간을 겹치지 않게 작업을 하려한다면 중간에 비는 데이터가 생길 수 밖에 없습니다.
어쩔 수 없이 중복을 허락하면서 병합을 실행해야 합니다.
갑자기 업비트 틱데이터 받는 법을 할 수는 없으니 데이터값만 가지고 해보겠습니다.
추후에 기회가 되면 업비트 데이터 조회방법을 포스팅하겠습니다.
df_1 과 df_2 의 데이터를 중복 없이 병합하고 싶습니다.
데이터를 봐도 중복데이터가 있는것을 볼 수 있습니다.
df_1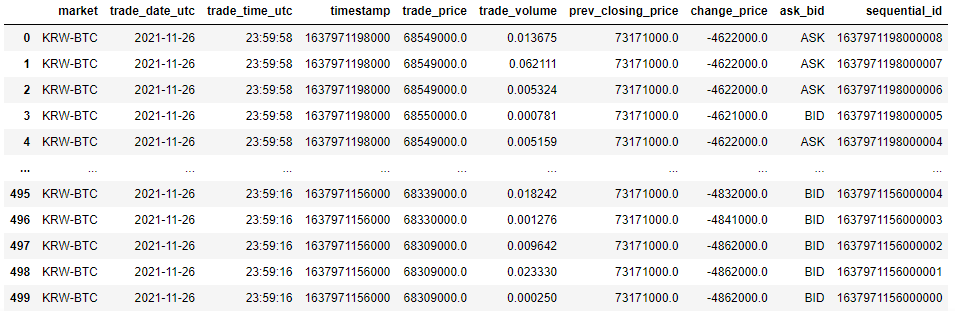
df_2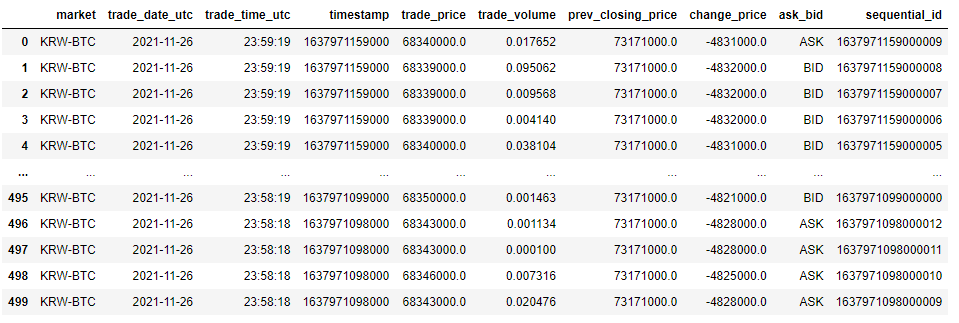
df_1는 23:59:16에서 끝났고 df_2 는 23:59:19 부터 시작해서 이 데이터를 연결하면 중복이 생깁니다.
하지만 위에서 배운 메쏘드가 있기 때문에 걱정없이 병합을 할 수 있습니다.
일단 합칩니다. 그래야 중복을 확인할 수 있으니까요.
df = pd.concat((df_1,df_2))
df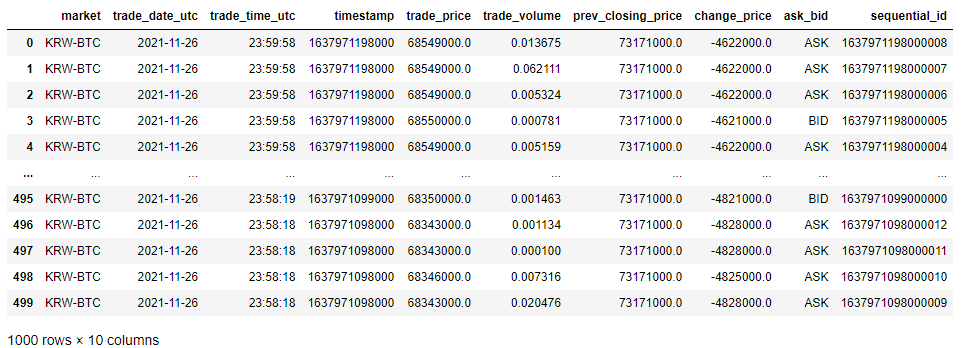
인덱스 처리를 하지 않았지만 어쨋든 1000개의 데이터를 합쳤습니다.
이제 중복을 제거합니다.
파라미터에 key값을 설정하지 않으면 전체 column으로 인지하기 때문에 안 쓰셔도 됩니다.
df_drop = df.drop_duplicates()
df_drop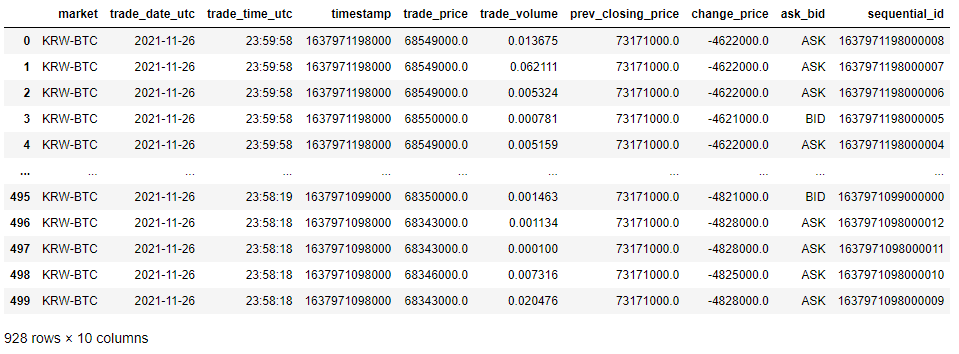
100개에서 928로 줄었습니다. 72개의 중복데이터가 있었나봅니다.
실제로 중복데이터가 72개 있는지 확인해보겠습니다.
df[df.duplicated()==True]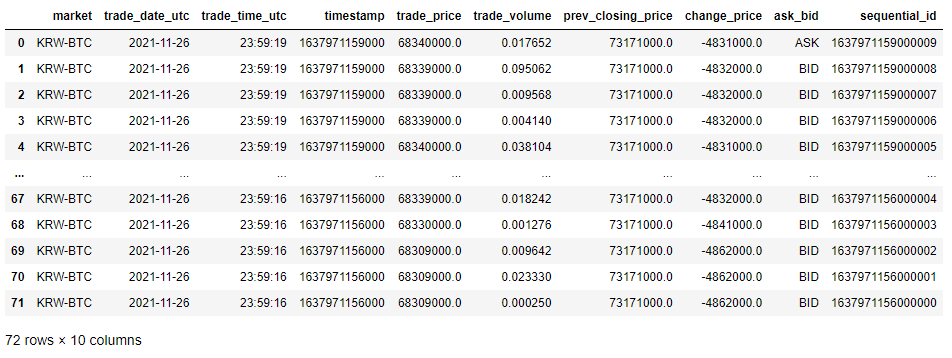
정확하게 72개의 중복데이터가 있었습니다.
중복데이터 제거 방법을 정리하면 다음과 같습니다.
1. 데이터프레임 중복을 포함해서 병합하기(concat or append)
2. drop_duplicates()를 이용해 중복데이터 없애기
생각보다 간단합니다. 이상 중복데이터 제거 방법이었습니다.
제 글이 도움이 되었기를 바랍니다.
관련 포스팅
[Python/Pandas] - [Pandas] DataFrame 합치기(Merge)
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 빈 데이터프레임 만들기 (0) | 2021.12.29 |
|---|---|
| [Pandas] 특정한 컬럼의 행 올리기,내리기(shift) (2) | 2021.12.17 |
| [Pandas] notna,notnull (0) | 2021.08.14 |
| [Pandas]데이터프레임 로우와 컬럼 바꾸기(df.T) (0) | 2021.07.25 |
| [Pandas] 문자열을 여러개의 컬럼으로 나누기 (0) | 2021.07.24 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!