[Pandas] 특정한 컬럼의 행 올리기,내리기(shift)
- Python / Pandas
- 2021. 12. 17.
반응형
반응형
데이터 작업을 하다보면 다른 행과 계산할 경우 shift를 이용해 해결할 수 있습니다.
for문으로 인덱스를 일일히 돌리지 않아도 되고
필요에 따라 컬럼을 추가해서 눈으로 확인해도 되지만
다른 행과 계산하려고 일일히 컬럼을 추가하는 번거로움을 줄일 수 있습니다.
shift()

period에 넣은 값만큼 행이 밀립니다.
행전체를 아래로 내리고 싶다면 양의정수를 넣고 위로 올리고 싶다면 음의 정수를 넣습니다.
특정 컬럼을 넣고 싶다면 특정 컬럼만 shift를 진행합니다.
확인을 위해 새로운 컬럼을 만들어 Open 값을 아래로 내린 값을 넣겠습니다.
df
df['Open_shift'] = df['Open'].shift(1)
Open_shift라는 컬럼에 Open 값이 하나씩 내려왔습니다.
바로 전 행과의 계산이 필요할때가 있습니다.
이럴 때도 shift를 활용해 계산할 수 있습니다.
당일종가 - 전일종가를 실행해보겠습니다.
일자는 오름차순이므로 전일종가를 shift(1)로 끌어내려 계산을 합니다.
df['Change_Close'] = df['Close']-df['Close'].shift(1)
Change_Close 컬럼에 계산이 잘 되어서 나온 것을 볼 수 있습니다.
그룹별로 행올리기 내리기
groupby를 이용해 그룹별로 행 올리기 내리기를 할 수 있습니다.
df를 Volume 이 30만보다 큰것과 작은 것으로 구분하겠습니다.
df['Classify_Volume'] = np.where(df['Volume']>300000,1,0)
groups = df.groupby('Classify_Volume')
groups의 기준대로 그룹화되었고 이 중 Close 값을 한칸 아래로 밀어내겠습니다.
df['groups_Close'] = groups['Close'].shift(1)
그러면 그룹별로 모아진 데이터에서 옮겨진 것을 확인할 수 있습니다.
df[df['Classify_Volume']==1]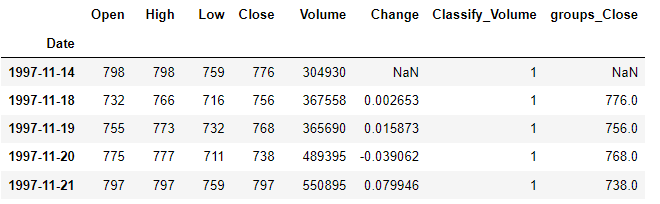
전체 데이터를 보면 그룹별로 따로노는 것을 보실 수 있습니다.
df.head(20)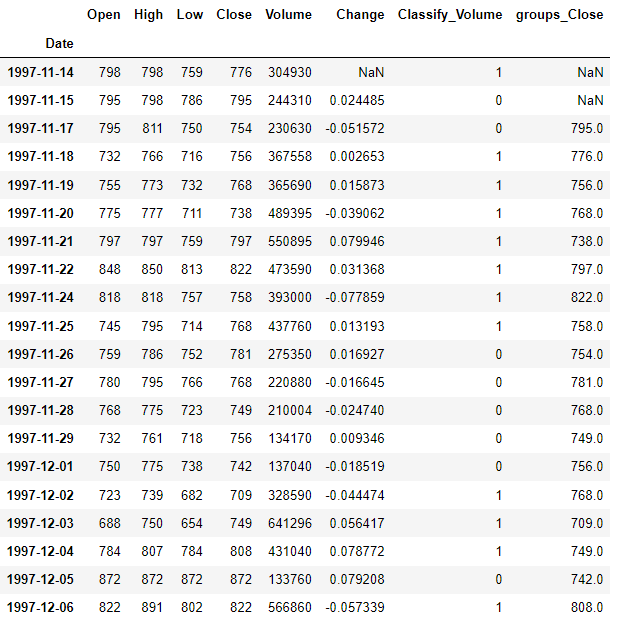
관련 포스팅
'Python > Pandas' 카테고리의 다른 글
| [Pandas] series 인덱스로 값 찾기 (0) | 2022.01.10 |
|---|---|
| [Pandas] 빈 데이터프레임 만들기 (0) | 2021.12.29 |
| [Pandas] 중복데이터 병합하기(column이 모두 같은 경우) (3) | 2021.12.03 |
| [Pandas] notna,notnull (0) | 2021.08.14 |
| [Pandas]데이터프레임 로우와 컬럼 바꾸기(df.T) (0) | 2021.07.25 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!