[Pandas] 함수 적용하기(map,apply, applymap)
- Python / Pandas
- 2022. 2. 4.
판다스 내에서 함수처리 하는 방법입니다.
파이썬으로 할 수 있지만 판다스 메쏘드로 간단한 함수를 정의할 수 있다는 게 큰 장점이고
메모리 절약도 할 수 있습니다.
map, apply, applymap 세가지 메쏘드를 알아볼까 합니다.
map
map 은 수학시간에 배운 합성함수와 같습니다.
인덱스가 잘 맞춰져 있다면 값 전환을 할 수가 있습니다.
x, y를 다음과 같이 정의하겠습니다.
import pandas as pd
x = pd.Series({'one':1,'two':2,'three':3})
y = pd.Series({1:'triangle',2:'square',3:'circle'})

map을 이용해 x에서 y로 값 전환을 합니다.
x.map(y)
mapd을 반대로 하면 NaN로 나옵니다.
y.map(x)
값이 일부만 있을때는 비어있는 값은 NaN 처리를 하고 map을 진행합니다.
y = pd.Series({1:'triangle',2:'square'})
x.map(y)
정리를 하면 그림과 같이 인덱스를 타고 값을 선택하게끔 하는 기능이 map의 기능입니다.
하지만 map은 인덱스에 따라서 값을 전환하는 기능이니DataFrame에서는 사용할 수 없고 Series에서만 할 수 있습니다. DataFrame에서는 map을 하고 싶다면 join과 replace로 대체합니다.
apply
apply는 Series와 DataFrame에서 lambda 함수를 쓸 수 있는 메쏘드라고 볼 수 있습니다.
대개는 apply를 안 쓰고 해결할 수 있지만 코드절약과 고급진 방법을 뽐낼때 종종 사용할 수 있습니다.
아래와 같이 Series에서도 가능합니다.
x.apply(lambda v:v*2)
DataFramep에서도 가능합니다. row, column이 존재하기 때문에 축을 잘 설정해주어야 합니다.
예를 들어 각 column의 합계를 구하고 싶을때는 axis=0로 하면 되고 row의 합계는 axis=1로 합니다.
일반적인 (4,3) 행렬을 DataFrame에 옮겨서 apply 합계를 실행해보겠습니다.
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(4,3),columns=['a','b','c'])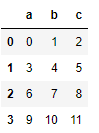
#column 합계
df.apply(lambda x:x.sum())

#row 합계
df.apply(lambda x:x.sum(),axis=1)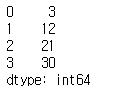
column추가할 때도 apply를 활용할 수 있는데 lambda에 적당한 함수를 넣어서 값 계산을 할 수 있습니다.
아래 예는 a,b column을 row별로 더했습니다.
df['a+b'] = df.apply(lambda r:r.a+r.b,axis=1)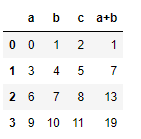
applymap
applymap은 apply와 형식은 비슷한데 접근하는 개체가 개별적입니다. 즉, 각 원소에 lambda를 적용하는 경우입니다.
lambda에서 if 와 같이 조건을 넣을 수 있는데 apply에서는 column이나 row 전체가 움직이게 설계가 된다면
applymap은 각 원소에 설계가 됩니다.
df.applymap(lambda x:'%.2f'% x)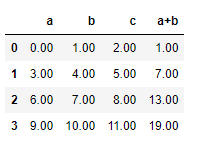
apply로 같은 요청을 하면 오류가 나옵니다.
df.apply(lambda x:'%.2f'% x)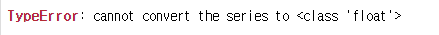
if-else를 쓰면 applymap이 무엇인지 좀 더 와닿습니다.
df.apply(lambda x : '%.2f'% x if (x > 5) else x)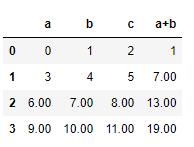
관련 포스팅
[Python] Lambda(람다) 함수
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 데이터프레임 행(row) 추가하기 (4) | 2022.02.10 |
|---|---|
| [Pandas] 데이터프레임 기준 컬럼 정하기(Pivoting) (0) | 2022.02.07 |
| [Pandas] SQL 데이터베이스 저장, 불러오기 (0) | 2022.01.31 |
| [Pandas] replace로 값 변경하기 (0) | 2022.01.28 |
| [Pandas] CSV 저장,불러오기 (2) | 2022.01.19 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!