[Pandas] 데이터프레임 기준 컬럼 정하기(Pivoting)
- Python / Pandas
- 2022. 2. 7.
데이터는 하나씩 쌓이는 형식으로써 저장됩니다.
보통 csv나 엑셀 파일, 데이터베이스 형태로 저장이 되는데 쌓이는 형식이다 보니 종종 내가 원하는 방식으로 규격화되지 않거나 컬럼은 다르지만 값은 중복하는 데이터가 저장되기 마련입니다.
그런데 중복데이터가 눈으로 봐도 전체 데이터의 카테고리 역할을 하는 컬럼이라면 카테고리 역할을 잘 할 수 있게 재배치를 하고 싶은 욕구가 생깁니다.
이럴 때 기준점을 새로 만들어 배치하는 방법이 있습니다.
바로 pivot()입니다. pivot을 이용해 세련되게 데이터를 바꿀 수 있습니다.
pivoting
데이터프레임을 구성하려면 index, column, values 세 개의 역할이 반드시 필요합니다.
pivoting은 원래 구성된 데이터의 컬럼의 역할 정하기로 볼 수 있습니다.
판다스에서 pivot은 다음의 파라미터를 같습니다.
DataFrame.pivot(index=None, columns=None, values=None)
데이터프레임의 기본 구성인 index,column,values를 정해주면 됩니다.
- index : 인덱스로 보낼 컬럼, 인덱스를 정하지 않으면 기존 인덱스로 정해짐
- columns : 컬럼으로 보낼 컬럼
- values : value 값으로 보낼 컬럼

그림을 보면 A 컬럼의 값이 인덱스 역할을 하고 B 컬럼의 값이 컬럼역할을, C 컬럼의 내용은 A와 B에 대응하는 내용값이 되었습니다.
pivoting 활용 예
15개의 임의의 컬럼을 만들어 구성하였습니다.
import pandas as pd
interval = [0,0,0,1,1,1,2,2,3,3,3,4,4,4,5]
axis = ['x','y','z','x','y','z','x','y','z','x','y','z','x','y','z']
values = [0,0.5,1.0,1.5,2.0,2.5,3.0,4.0,3.5,3.0,2.5,2.1,1.5,1.7,4.0]
df = pd.DataFrame({'interval':interval,'axis':axis,'value':values})
df axis를 기준으로 보고 싶다면 pivot의 columns 부분은 axis 가 됩니다.
index를 coordinaes로 정한다면 일종의 좌표로써 작용을 할 것입니다.
df.pivot(index='interval',columns='axis',values='value')
값이 없는 경우에는 NaN 처리가 되었고 x,y,z 와 0,1,2,3,4,5에 따라 어떤 값을 갖는지 한눈에 볼 수 있습니다.
인덱스를 넣지 않으면 기존 인덱스를 따라갑니다.
df.pivot(columns='axis',values = 'value')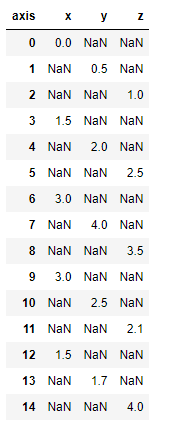
value를 넣지 않으면 axis를 기준으로 기존 컬럼의 내용이 모두 나오게 됩니다.
df.pivot(columns='axis')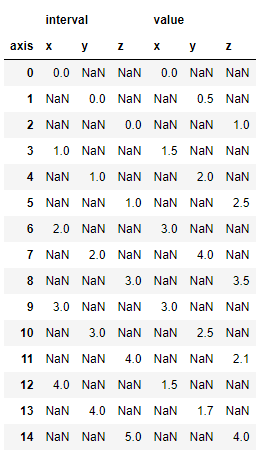
파라미터를 채울 때 컬럼은 반드시 채워야 합니다.
pivot이 기준 컬럼을 결정하는 것이기 때문에 그렇지 않으면 오류가 발생합니다.
df.pivot(values='value')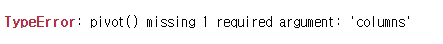
또한 index로 쓸 컬럼과 columns으로 쓸 컬럼이 같은 중복데이터가 있다면 오류가 발생합니다.
따라서 중복하는 경우 정제를 한 후 pivot을 사용하는 것이 좋습니다.
interval 이 1이었던 것을 0으로 바꾸고 pivot을 진행해보겠습니다.
dup_df = df.replace({'interval':1},0)
dup_df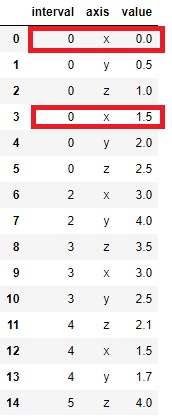
pivot을 진행하면 다음과 같이 오류가 뜹니다.
dup_df.pivot(index='interval',
columns='axis',values='value')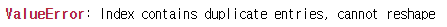
마치며...
pivot은 컬럼에 카테고리를 형성할만한것이 있는경우 재배치를 통해 편하게 데이터를 볼 수 있게 만들 수 있습니다.
pivot을 적용할 수 있는 데이터가 적은 편이지만 적합한 데이터가 나오거나 유도를 해서 유용하게 쓸 수 있을 것 같습니다.
관련 포스팅
[Pandas] replace로 값 변경하기
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 데이터프레임 재구조화하기(Stack,Unstack) (0) | 2022.02.22 |
|---|---|
| [Pandas] 데이터프레임 행(row) 추가하기 (4) | 2022.02.10 |
| [Pandas] 함수 적용하기(map,apply, applymap) (0) | 2022.02.04 |
| [Pandas] SQL 데이터베이스 저장, 불러오기 (0) | 2022.01.31 |
| [Pandas] replace로 값 변경하기 (0) | 2022.01.28 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!