[Pandas] 데이터프레임 행(row) 추가하기
- Python/Pandas
- 2022. 2. 10.
데이터프레임에서 행 추가하는 방법입니다.
이전에 컬럼(column) 추가에 대해서 포스팅은 해놨는데
row 추가는 하지 않았더라고요 ㅎㅎ
데이터프레임에 row 추가방법 두가지에 대해 포스팅을 하겠습니다.
- loc로 행 추가하기
- append로 행 추가하기
loc로 행 추가하기
컬럼에서 했던 방법 그대로 loc에서도 적용됩니다.
판다스는 일관성이 있어서 비슷비슷합니다.
import pandas as pd
sample = [('Json','34','Developer')]
df = pd.DataFrame(sample,columns=['Name','Age','Job'])
df
다음과 같이 만든 데이터 프레임에 행 추가를 해보겠습니다.
df.loc[1]=['Harry','25','Analyst']
df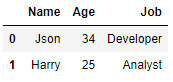
컬럼에 맞게 해주는 게 키포인트입니다. 값이 맞지 않으면 오류가 발생합니다.
df.loc[2]=['Lucy','25']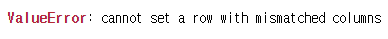
append를 이용한 행 추가
append를 이용해서 행 추가가 가능한데 약간 번거롭습니다.
컬럼에 매칭해서 일일히 넣어주어야 하고 딕셔너리로 넣어주어야 하기 때문에 ignore_index=True 를 반드시 넣어주어야 합니다.
앞에서 loc로 Harry를 추가한 데이터프레임을 그대로 쓰겠습니다.
df.append({'Name': 'Rax','Age':30,'Job':'CEO'},ignore_index=True)
df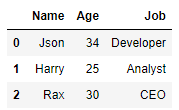
컬럼이 많다면 위와 같이 일일히 써야한다면 힘들겁니다.
컬럼이 많을때는 어떻게 해야할까요?
데이터프레임은 컬럼만 리스트형태로 가져올 수 있으니
컬럼만 가져와서 for문으로 딕셔너리를 위와 같이 만듭니다.
만든 딕셔너리를 가지고 append로 행 추가를 실행합니다.
예제
다음 예제로 loc와 append를 적용해보겠습니다.
ddf
위 ddf에 딕셔너리 내용을 추가하겠습니다.
먼저 loc입니다.
아주 간단하게 마칠 수 있습니다.
exam_dict = {'삼성전자':(60000,50000),'카카오':(100000,95000)}
for key,value in exam_dict.items():
ddf.loc[key] = value
ddf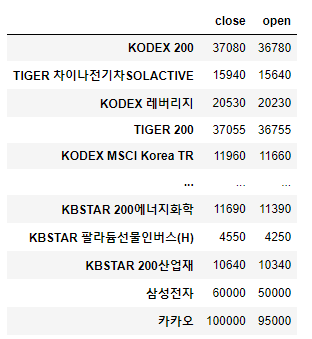
append는 약간 복잡합니다. ignore_index=True를 적용한 상태에서 추가를 해야하므로 index를 포함해서 넣으려고 한다면 잘 되지 않습니다.
따라서 index에 이름이 있어야 하고 reset_index를 했다가 행 추가 후 다시 set_index를 합니다.
index에 이름이 있어야 하는 이유는 이름이 없다면 reset_index를 할 때 'index' 로 컬럼이름이 붙여지는데
데이터프레임 안에 index를 여러개 지정할 수 있어서 사실상 index가 여러개가 있습니다. 그래서 다른 인덱스에 배치되는 현상이 발생합니다.
행 추가가 잘 된 경우입니다.
{컬럼 네임1: 값1,컬럼 네임2: 값2,...} 을 계속 붙여 딕셔너리를 만들고
데이터프레임에 추가하고 다시 딕셔너리를 만들어서 추가하는 방식입니다.
메모리 소비가 많은 방식이긴 하지만 어쨋든 행추가를 할 수 있습니다.
append_dict = {}
ddf.index.name = 'Name'
ddf.reset_index(inplace=True)
for key,value in exam_dict.items():
append_dict[ddf.columns[0]] = key
append_dict[ddf.columns[1]] = value[0]
append_dict[ddf.columns[2]] = value[1]
ddf = ddf.append(append_dict,ignore_index=True)
ddf.set_index('Name',inplace=True)
append 인덱스 처리의 중요성
index 이름을 정해주지 않는다면 어떨때는 제대로 되고 어떨때는 엉뚱한 곳으로 가게 됩니다. 그 이유는 level_0으로 잡혀있는 인덱스 때문인데 실제로 df.index로 인덱스를 찾아보면 나오지 않는 경우가 있기 때문에 안전하게 하기 위해서는 인덱스 이름을 만들고 하는것을 추천합니다.
append_dict = {}
ddf.reset_index(inplace=True)
for key,value in exam_dict.items():
append_dict[ddf.columns[0]] = key
append_dict[ddf.columns[1]] = value[0]
append_dict[ddf.columns[2]] = value[1]
ddf = ddf.append(append_dict,ignore_index=True)
다음으로 인덱스 이름을 만들고 그대로 해도 될 것 같다는 생각이 들 수 있는데 이것도 되질 않습니다.
append_dict = {}
ddf.index.name = 'Name'
for key,value in exam_dict.items():
append_dict[ddf.index.name] = key
append_dict[ddf.columns[0]] = value[0]
append_dict[ddf.columns[1]] = value[1]
ddf = ddf.append(append_dict,ignore_index=True)
ddf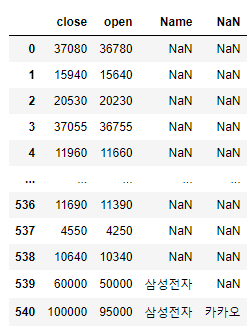
마치며
loc와 append 를 이용한 데이터프레임 행 추가하는 방법이었는데요.
아무래도 loc가 훨씬 편하고 쉽습니다.
그래도 append로도 할 수 있는 걸 알고 있으면 다양한 응용을 할 수 있지 않을까 싶습니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 특수문자 제거하기 (0) | 2022.02.24 |
|---|---|
| [Pandas] 데이터프레임 재구조화하기(Stack,Unstack) (0) | 2022.02.22 |
| [Pandas] 데이터프레임 기준 컬럼 정하기(Pivoting) (0) | 2022.02.07 |
| [Pandas] 함수 적용하기(map,apply, applymap) (0) | 2022.02.04 |
| [Pandas] SQL 데이터베이스 저장, 불러오기 (0) | 2022.01.31 |