[파이썬 자료구조] HashTable 충돌 시 적용 알고리즘
- Python/알고리즘
- 2022. 12. 25.
해쉬테이블(HashTable)은 주어진 공간에서 값을 저장하게 되면 충돌이 일어나게 됩니다. 이를 처리하는 기법 2가지를 소개합니다.
사실 더 많은 방법이 있는데 어짜피 파이썬에서는 딕셔너리로 다 커버가 되기 때문에 연습용으로 보시면 좋을 것 같습니다.
아래 내용을 보시면 공간의 제약이 거의 없는 딕셔너리의 장점이 얼마나 큰지 느끼실 수 있을겁니다. 참고로 실제 딕셔너리처럼 key값을 잘 정리하지는 않았습니다.
해쉬테이블이 충돌하는 이유
데이터는 많은데 공간은 제약되어있다면 충돌이 일어날 수밖에 없습니다. 예를 들어, 데이터가 만약 9개가 있고 공간이 8개까지밖에 없다면 해쉬테이블의 원리상 무조건 1개 이상은 충돌이 일어날 수밖에 없습니다.
공간을 넓힐 수 있다면 최대한 넓히는 게 좋지만 현실세계는 메모리가 한정되어있고 저장용량도 한정되어 있습니다. 그렇기 때문에 충돌에 대한 고민이 없어지지 않습니다. 알고리즘을 설계할 때 충돌을 어떻게 최소화할 수 있는지 그리고 충돌되었을 때 어떤 방식으로 처리할지를 잘 생각해놔야 합니다.
해시테이블 충돌 시 알고리즘 2가지
충돌은 불가피하니 충돌시 데이터 처리하는 알고리즘 2가지를 소개합니다.
Chaining 기법
Chaining 기법은 개방 해쉬 또는 Open Hashing 기법 중 하나로 해쉬 테이블 저장공간 외의 공간을 활용하는 기법입니다.
즉, 충돌이 일어나면, 링크드 리스트로 데이터를 추가로 뒤에 연결시켜서 저장하는 기법입니다.
파이썬은 리스트가 있기 때문에 링크드 리스트를 반드시 만들 필요가 없습니다. 파이썬에서 Chaning 기법을 적용한다면 모든 공간을 리스트형식으로 만들어서 값이 중복되면 리스트에 하나씩 추가하는 방식이 됩니다.

장점은 모든 값을 넣을 수 있다는 것과 데이터가 일단 저장이 되므로 메모리 소모가 적은 것입니다.
하지만 어쨋든 충돌이 일어나는 곳에서 계속 데이터가 늘어나게 되면 한 공간에만 저장되는 쏠림현상이 일어날 수 있습니다. 검색의 입장에선 좋진 않습니다.
동작방식
실제로 코드로 어떤 아웃풋이 나오는 확인해보시기 바랍니다.
일부러 충돌하는 형식을 만들기 위해 ord를 사용해 key를 만들어서 진행했습니다.
hash_table = list([0 for i in range(8)])
def get_key(data):
return ord(data)
def hash_function(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
hash_table[hash_address][index][1] = value
return
# 배정받은 공간이 같아서 충돌이 일어난다면 리스트에 추가
hash_table[hash_address].append([index_key, value])
else:
hash_table[hash_address] = [[index_key, value]]
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
return hash_table[hash_address][index][1]
return None
else:
return None같은 공간에 들어갈 데이터를 찾아 넣어보겠습니다.
print(get_key('DA'),get_key('Lan'))
save_data('DA','0101234567')
save_data('Lan','0102582582')
hash_table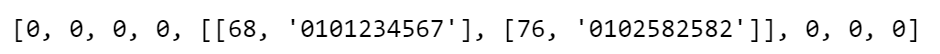
실제로 hash()함수로 바꾸고 8개의 공간에 9개의 데이터를 넣어보겠습니다. 그러면 무조건 1개 이상 충돌이 나므로 chaning 기법에 의해 공간 안에 리스트 길이가 2 이상인 경우가 생깁니다.
data = [('Ann','01012345678'),('David','01013579246'),('Becy','01024681357'),('Jake','01011235813'),('Joey','01011117777'),('Lily','01022558811'),('Jenny','01014916253'),('Jessy','01044822811'),('Rose','01025625232')]
for index in data:
save_data(index[0],index[1])
hash_table
Linear probing 기법
Linear probing은 - 폐쇄 해쉬 또는 Close Hashing 기법 중 하나로 해쉬 테이블 저장공간 안에서 충돌 문제를 해결하는 기법입니다. 즉, 충돌이 일어나면 해당 hash address의 다음 address부터 맨 처음 나오는 빈공간에 저장하는 기법입니다. chaining처럼 한쪽 쏠림현상을 없애고 저장공간 활용도를 높이기 위한 기법입니다.

삭제 처리 문제
hash address 이후 인덱스에 대해서 빈공간을 찾아들어가는 방식이라서 데이터가 공간보다 많다면 이전 저장한 데이터 값의 처리가 난감해집니다. 일반적으로 이전 데이터가 삭제가 되고 덮어쓰여지는데 파이썬은 대개 인덱스처리가 자동으로 이루어지지만 인덱스 처리를 따로 해야하는 언어는 검색시 충돌 인덱스 이후의 값이 검색이 안 될 수도 있습니다.
동작방식
동작방식은 앞에서 언급한 것처럼 충돌시 hash_address 이후 인덱스부터 빈공간을 찾아다닙니다.
마찬가지로 9개의 데이터로 구현해보았습니다.
9개가 다 채워지지 않고 일부 데이터가 삭제될 것입니다.
hash_table = list([0 for i in range(8)])
def get_key(data):
return hash(data)
def hash_function(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(hash_address, len(hash_table)):
#hash_address 인덱스 이후 빈공간 찾은 후 데이터저장
if hash_table[index] == 0:
hash_table[index] = [index_key, value]
return
elif hash_table[index][0] == index_key:
hash_table[index][1] = value
return
else:
hash_table[hash_address] = [index_key, value]
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(hash_address, len(hash_table)):
if hash_table[index] == 0:
return None
elif hash_table[index][0] == index_key:
return hash_table[index][1]
else:
return None
data = [('Ann','01012345678'),('David','01013579246'),('Becy','01024681357'),('Jake','01011235813'),('Joey','01011117777'),('Lily','01022558811'),('Jenny','01014916253'),('Jessy','01044822811'),('Rose','01025625232')]
for index in data:
save_data(index[0],index[1])
hash_table
충돌예방을 위해 할 수 있는 것
충돌방지를 위해서는 2가지 조치를 취할 수 있습니다.
- 공간을 늘린다.
- 해쉬함수를 좋은 걸로 쓴다.
공간을 최대한 늘리던지 그게 아니면 충돌이 잘 안 되는 해쉬함수를 쓰면 됩니다.
해쉬함수의 중요성
해쉬테이블의 충돌은 불가피합니다. 충돌을 왠만하면 피하는게 상책입니다. 그러기 위해선 해쉬함수를 잘 정해서 충돌을 방지합니다.
해쉬 함수를 거쳐 나온 hash_address를 고정값으로 만드는 것도 한 방법입니다. hash() 함수는 키 값 고정이 안되서 이를 고정값으로 만들 수 있는 라이브러리가 있습니다. hashlib라는 라이브러리인데 SHA1, SHA224, SHA256, SHA384, SHA512 등 좋은 해쉬함수를 사용할 수 있습니다.
키값을 고정시켜야 하는 이유(시간복잡도)
키값을 고정시켜야 하는 또하나의 이유는 충돌 기복을 줄일 수 있습니다.
해쉬테이블의 시간복잡도는 다음과 같습니다.
- 충돌이 하나도 일어나기 않으면 O(1)
- 충돌이 모두 일어나면 O(n)
데이터가 많으면 많을수록 충돌이 일어날 확률이 높아지는데 충돌이 안 일어난다면 (그럴리는 없겠지만) 시간복잡도를 많이 줄일 수 있습니다.
SHA-1 사용방법
해쉬함수를 SHA-1로 만들어 진행을 해보겠습니다.
SHA-1 사용방법은 간단합니다.
그냥 encoding입니다.
import hashlib
data = 'Ann'.encode()
sha1_convert = hashlib.sha1()
sha1_convert.update(data)
hex_dig = sha1_convert.hexdigest()
dig = sha1_convert.digest()
print (dig, hex_dig)
문자를 dig는 0~255 바이트 값으로 다시 만들었고 hex_dig는 16진수로 나타내었습니다.
해쉬테이블을 진행할 때는 숫자가 편하니 16진수를 사용하면 됩니다.
hash_table = list([0 for i in range(8)])
def get_key(data):
encode = data.encode()
sha1_convert = hashlib.sha1()
sha1_convert.update(encode)
hex_dig = sha1_convert.hexdigest()
return int(hex_dig,16)
def hash_function(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
hash_table[hash_address][index][1] = value
return
hash_table[hash_address].append([index_key, value])
else:
hash_table[hash_address] = [[index_key, value]]
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
return hash_table[hash_address][index][1]
return None
else:
return None
data = [('Ann','01012345678'),('David','01013579246'),('Becy','01024681357'),('Jake','01011235813'),('Joey','01011117777'),('Lily','01022558811'),('Jenny','01014916253'),('Jessy','01044822811'),('Rose','01025625232')]
for index in data:
save_data(index[0],index[1])
hash_table
마치며
해쉬테이블의 충돌 방지 방법에 대해 알아보았는데 파이썬에서는 딕셔너리로 하기 때문에 아마 거의 쓰진 않을 것 같습니다. 그래도 기법을 알고 있으면 다른 언어를 사용할 때 많은 도움이 될 거라 생각합니다.
관련 포스팅
'Python > 알고리즘' 카테고리의 다른 글
| [파이썬 알고리즘] 버블 정렬(bubble sort)이란? (0) | 2023.01.18 |
|---|---|
| [파이썬 알고리즘] 재귀용법(recursive call, 재귀호출) (2) | 2023.01.12 |
| [파이썬 자료구조] 해쉬테이블 구현해보기 (0) | 2022.12.22 |
| [Python]속도개선 - Recursive pandas (0) | 2021.09.18 |
| [Python] 속도개선 -알고리즘편(Recursive) (0) | 2021.09.16 |