반응형
반응형
데이터 프레임의 데이터를 많이 다루는데 범주를 만들어야 하는 경우가 있습니다.
범주를 나누는 방법을 알려드립니다.
데이터
랜덤으로 만든 int와 float를 각각 컬럼으로 하고 데이터프레임을 예제로 하겠습니다.
import pandas as pd
import numpy as np
import random
df = pd.DataFrame({'int':random.sample(range(100),30),'float':np.random.randn(30)})
df
1. 동일길이로 나누기
데이터를 동일길이로 나눌려면 pd.cut()을 사용합니다. pd.cut()은 시리즈를 input값으로 해야합니다.
파라미터는 다음과 같습니다.
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', ordered=True)| 파라미터 | 데이터타입 | 설명 |
| x | array-like | 동일길이로 나눌 array. 반드시 1-dimension이어야 한다. |
| bins | int, sequence of scalars, or IntervalIndex | 범주를 정한다. |
| right | bool | default True True이면 오른쪽 끝을 포함 False면 오른쪽 끝을 포함하지 않음. |
| labels | array or False | default None 임의로 레이블 지정. False면 빈의 정수표시자만 반환. order=False면 레이블을 제공해주어야 한다. |
| retbins | bool | default False, bins을 반환할지 여부. bins이 스칼라일떼 유용. |
| precision | int | default 3 범주가 표시될 소숫점 자릿수 , 3이면 소수점 3째자리까지 반올림 |
| include_lowest | bool | default False, 첫번째 인터벌이 왼쪽을 포함할 것인지 여부 |
| duplicates | {‘raise’, ‘drop’} | default raise 가장자리가 고유하지 않은 경우, ValueError를 일으킬지 삭제할지 여부 |
| ordered | bool | default True 라벨 순서 여부. True이면 정렬됨. |
데이터를 6가지 범주로 나눠보겠습니다. 이에 맞게 알아서 길이를 정해줍니다.
cutting_int = pd.cut(df.int,6)
cutting_int.tail()범주를 어떻게 했는지 맨 밑에 보여줍니다.
groupby 활용
범주를 만들었으니 범주별로 어떤 통계값을 갖는지 groupby를 통해 확인할 수 있습니다.
group_int = df.int.groupby(cutting_int)
group_int.agg(['count','mean','std','min','max'])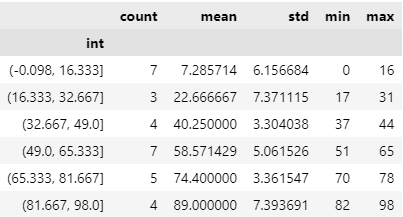
2. 동일 개수로 나누기
이번엔 범주 개수가 아니라 데이터 갯수를 동일하게 만드는 방법입니다. pd.qcut()을 사용합니다.
파라미터는 다음과 같습니다.
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')
| 파라미터 | 데이터타입 | 설명 |
| x | 1d ndarray or Series | 범주를 나눌 시리즈 또는 1d ndarray |
| q | int or list-like of float | 범주를 나눌 갯수 |
| labels | array or False | default None, 임의로 지정 labels 지정할시 따로 정해주어야 한다. 대신 q와 동일한 갯수어야 한다. |
| retbins | bool | optional, (bins,labels)로 반환할지 여부. bin이 스칼라로 제공되는 경우 유용. |
| precision | int | optional, bins가 표시될 소수점 자리, 디폴트 3 |
| duplicates | {‘raise’, ‘drop’} | default raise bin 가장자리가 고유하지 않은 경우, ValueError를 발생시키거나 고유하지 않은 값을 삭제. |
라벨 지정해 범주화를 해보겠습니다.
dive_float = pd.qcut(df.float,5,labels=['Bad','Notbad','Medium','Good','Best'])
dive_float.tail()
groupby 활용
범주별로 통계를 만들어보겠습니다.
grouped = df.float.groupby(dive_float)
grouped.apply(summary).unstack()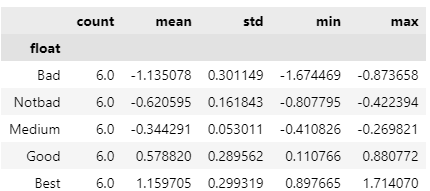
count가 모두 동일하게 6으로 된 것을 볼 수 있습니다.
관련 포스팅
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 엑셀 시트 여러개 불러오기(보다 쉬운 관리) (0) | 2023.07.24 |
|---|---|
| [Pandas] 내 맘대로 증가율 계산 (0) | 2023.02.06 |
| [Pandas] 시리즈 데이터프레임으로 바꾸기(to_frame) (0) | 2022.11.29 |
| [Pandas] 데이터프레임 중복행 제거하기(drop_duplicates) (0) | 2022.11.24 |
| [Pandas] 데이터 순위 구하기(rank) (0) | 2022.11.21 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!