[Pandas] 데이터프레임 중복행 제거하기(drop_duplicates)
- Python / Pandas
- 2022. 11. 24.
데이터프레임 중복행 제거하는 방법입니다.
이전 포스팅에서 컬럼이 같은 경우에서 중복데이터 병합하기 포스팅을 작성했었는데요. 그 내용 중에서 중복행 제거하는 방법을 언급했었습니다. 그렇지만 데이터 병합에 초점으로 쓴 글이라서 생략된 것이 꽤 있었습니다. 이번 포스팅에서는 drop_duplicates 그 자체에 초점을 맞출까 합니다.
중복행 제거하기
중복행을 제거하려면 drop_duplicates() 밖에 쓸 게 없습니다.
파라미터는 다음과 같습니다. 함수 실행 후 Return은 중복행 제거 후 데이터프레임으로 나타납니다.
DataFrame.drop_duplicates(subset=None, *, keep='first', inplace=False, ignore_index=False)- subset : column label or sequence of labels
- 해당 컬럼 기준으로 중복행 제거. 아무것도 쓰지 않으면 모든 컬럼을 기준으로 중복행 제거
- keep : {'fisrt','last',False}
- 디폴트 값은 first
- first : 첫번째에 위치한 것 빼고 다 지운다
- last : 마지막에 위치한 것 빼고 다 지운다
- False : 모두 다 지운다.
- inplace : True, False
- 디폴트 False
- True시 기존 데이터프레임에 반영된다.
- ignore_index : True, False
- 디폴트 False
- True시 인덱스 재구성(0,1,...,n-1)
예를 보면 다음과 같습니다.
머신러닝 연습 데이터로 많이 쓰이는 iris 데이터로 해보겠습니다.
iris
petal width (cm) 컬럼에서 같은 값을 제거하겠습니다.
iris.drop_duplicates('petal width (cm)')keep의 디폴트값이 first이기 때문에 앞에 인덱스값들을 보면 중복행중에서 가장 앞에 있는 값 빼고는 다 지워집니다.
맨 뒤에 값을 남기고 싶다면 last를 입력합니다.
iris.drop_duplicates('petal width (cm)',keep='last')first와 last의 0.2 를 비교해보면 인덱스 번호가 다른 걸 볼 수 있습니다.
0번이 맨 처음이었고 49번이 맨 마지막이었습니다.
중복데이터를 모두 지우고 싶다면 False를 입력합니다.
iris.drop_duplicates('petal width (cm)',keep=False)
모두 지워지고 2개의 행만 남았습니다.
2개 이상의 컬럼 비교해 중복행 제거
비교 대상이 2개 이상의 컬럼일 때
즉, A와 B 컬럼의 모두 같은 값을 갖는 경우일 때는 컬럼을 리스트로 작성해주면 됩니다.
iris.drop_duplicates(['petal width (cm)','sepal length (cm)'],keep='last')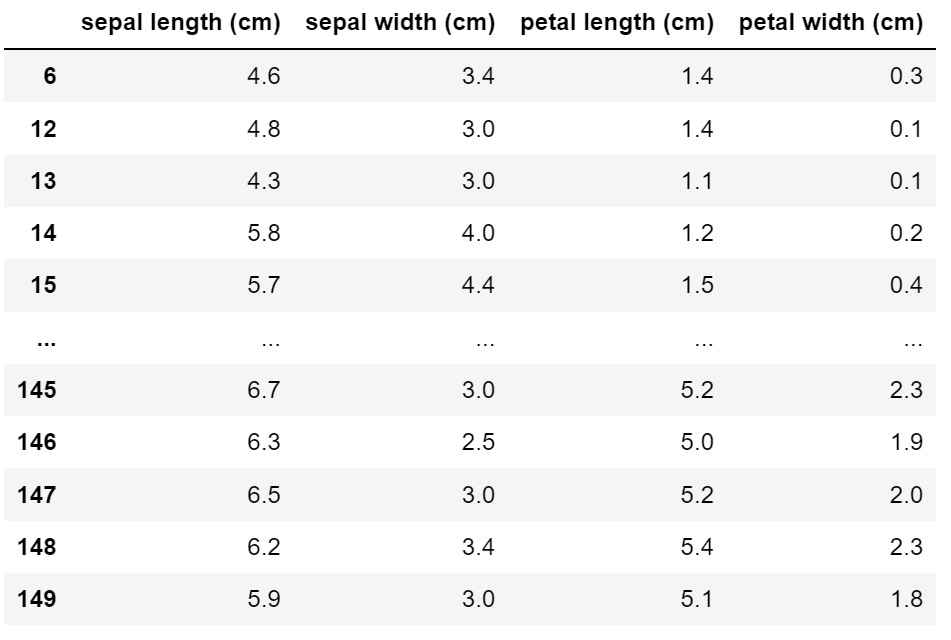
인덱스 리셋
중복행을 지우고 나서 인덱스를 재구성하지 않으면 loc를 쓸 때 애를 먹습니다.
만약 중복행을 지운 데이터프레임을 계속 써야한다면 인덱스를 리셋하는 습관을 기르는 게 좋습니다.
ignore_index = True 일 경우에는 reset_index와 같은 효과로 인덱스를 재구성합니다. 데이터프레임을 완성한 후 reset_index(drop=True) 를 해도 됩니다.
iris.drop_duplicates(['petal width (cm)','sepal length (cm)'],keep='last',ignore_index=True)
# 또는 reset_index(drop=True)
iris.drop_duplicates(['petal width (cm)','sepal length (cm)'],keep='last').reset_index(drop=True)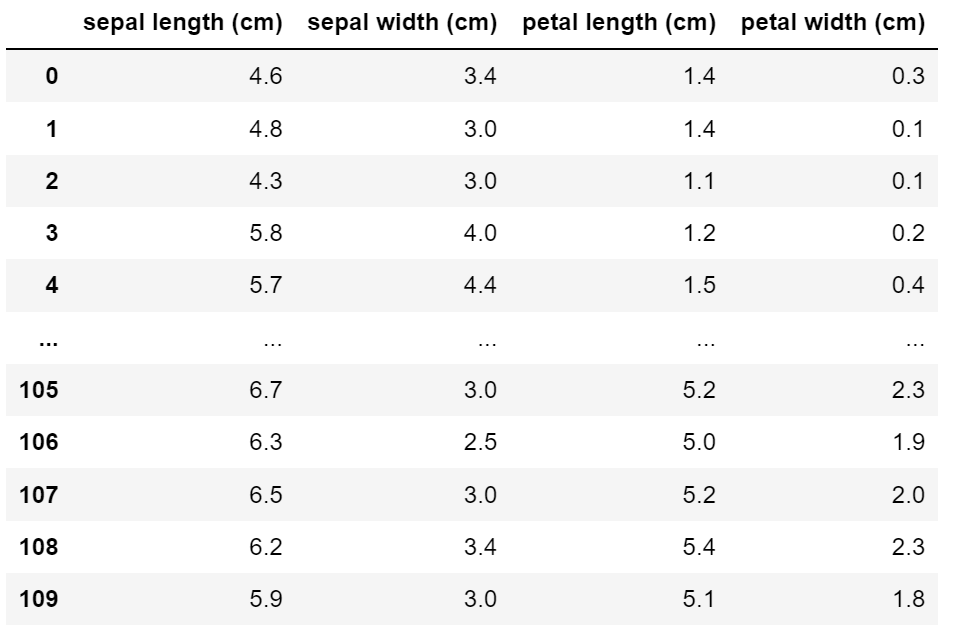
마치며
중복행 제거한 데이터프레임경우 기존 데이터프레임에 반영되지 않습니다.
기존 데이터프레임을 중복데이터 없는 데이터프레임으로 바꾸고 싶다면 inplace=True 를 꼭 넣어주거나 =를 써서 다시 정의하시길 바랍니다.
관련 포스팅
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 범주로 나누기(pd.cut(),pd.qcut()) (0) | 2023.01.01 |
|---|---|
| [Pandas] 시리즈 데이터프레임으로 바꾸기(to_frame) (0) | 2022.11.29 |
| [Pandas] 데이터 순위 구하기(rank) (0) | 2022.11.21 |
| pandas cheatsheet(코드요약) (0) | 2022.09.24 |
| [Pandas] 데이터프레임 리스트,numpy 배열로 변환 (0) | 2022.09.22 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!