Pandas Series 특징
- Python/Pandas
- 2020. 6. 9.
Pandas에 대해서 알아볼까 합니다. Pandas는 데이터 다룰 때 많이 쓰고 있고 데이터 사이언스를 하는데 있어서 반드시 잘 다루어야 하는 모듈 중에 하나이고 기본중의 기본 모듈이기도 합니다.
사실 파이썬에서도 리스트,튜플,딕셔너리를 가지고 데이터를 다룰 수 있습니다. 파이썬의 특유의 직관성 때문에 이런 자료구조를 다루는 것만으로도 굉장히 편리합니다. 그런데 좀 더 효율적인 부분을 생각한다면 pandas가 파이썬에 기본으로 내장되어 있는 것보다는 더욱 효율적인 작업을 할 수 있습니다. 그렇다고 Pandas만 주구장창 쓰는 건 아니고 필요에 따라서 리스트도 쓸 때도 있고 pandas에 있는 자료구조도 쓸수 있습니다. 그저 더욱 편리하고 잘 다룰 수 있는 방법을 추구하는 것 뿐입니다.
Pandas에는 두 종류의 자료구조가 있습니다. 바로 Series와 DataFrame입니다. Series 는 1차원 배열의 자료구조이고 DataFrame은 2차원 배열의 자료구조입니다. 그래서 이 두가지 자료구조를 잘 다루기만 한다면 데이터 사이언스에서 풍성하게 데이터 처리를 할 수 있습니다.
이번 포스팅에서는 Series 특징을 한 번 알아보겠습니다.
Series
Series는 1차원 배열의 자료구조입니다. 그러면 파이썬에 내장되어 있는 리스트와 튜플도 1차원 배열의 자료구조니깐 굳이 Series를 써야하는지 의문이 들 수도 있습니다. 저도 실제적으로 써보면 Series를 많이 쓰는 것 같진 않습니다. 그렇다고 아예 안 쓰는 것도 아닙니다. 경험상으로 보면 Series여야만 되는 부분이 있는게 분명해서 Series를 잘 알아놓으면 아마 그래도 Series를 모르는것보다는 좋지 않을까 싶습니다.
예를 보면서 특징을 알아보도록 합시다.
import numpy as np
import pandas as pd
s1 = pd.Series([1,2,3])
s1
s1이라는 이름으로 Sereis를 하나 만들었습니다. 그래서 출력을 해보았더니 리스트와는 다르게 나오는 것을 볼 수 있습니다. 리스트와 다르게 두 줄로 나오는데 맨앞의 0 1 2 는 인덱스를 의미하고 그 뒤에 1 2 3 은 자료를 의미합니다.
이렇듯 Series를 만들면 인덱스와 그에 매칭되는 자료를 한 눈에 볼 수 있습니다. 즉, 인덱스의 변환이 가능하다는 것을 의미합니다.

파라미터를 봐도 index를 파라미터에 하나로 여기고 있습니다. 이렇게 인덱스를 정할 수 있으면 훨씬 자료정리하기가 좋기 때문에 Series를 안 쓸래야 안 쓸 수가 없습니다.
파라미터에 있는것대로 name까지 추가해보겠습니다.
먼저 data와 index를 함께 명시를 해보겠습니다.
- data, index
s2 = pd.Series([1,2,3],[100,200,300])
s2
index를 [100,200,300]으로 설정하였습니다. 순서를 잘 해야하는데 data를 먼저 쓰고 index를 그 다음에 써야합니다.
- data,index,dtype
s3 = pd.Series(np.arange(5),np.arange(100,105),dtype=np.int32))
s3
dtype이 int32로 바뀌어서 나오는 것을 볼 수 있습니다. np.arange(5)도 1차원 자료구조이기 때문에 Series의 자료로써 쓸수 있습니다. 보시는 것처럼 s3이 오류없이 나옵니다.
- data,index,dtype,name
이 데이터의 고유 이름을 붙일 수 있는데 데이터가 많아지면 정리를 위해 쓰기도 합니다.
s4 = pd.Series(np.arange(5),np.arnage(100,105),dtype=np.int32,name='5_values')
s4
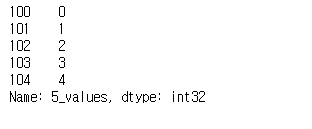
밑에 Name란이 더 생겨서 이 데이터의 이름이 무엇인지 알려줍니다.
이렇듯 리스트와는 다르게 인덱스와 이름을 정해주는 기능이 있어서 자료정리하는데 있어서 훨씬 편리합니다.
Series 인덱스 다루기
인덱스를 다뤄 보겠습니다. 방법은 리스트와 동일합니다.
- 인덱스를 통한 데이터 접근
s5= pd.Series(np.arange(5),np.arange(100,105),dtype=np.int32,name='5_values')
s5[100]
인덱스를 통한 접근은 리스트와 동일합니다.
- 데이터 업데이트
s5[105]= 10
s5
큰 어려움 없이 추가됩니다. 없는 인덱싱 넘버에 지정하면 되고 만약 이미 값이 있는 곳에 다시 지정을 하면 값이 업데이트 됩니다.
s5[100]=20
s5
Series index,value 분리
인덱스 재사용 방법을 보기 전에 Series 분리방법을 알려드릴까 합니다.(필요해요!!!)
Series는 마치 딕셔너리와 같이 index와 values가 분리가 됩니다.
s5.index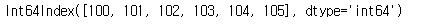
s5.values
- 인덱스 재사용
기존에 있던 인덱스를 재사용할 수 있습니다.
Series는 index와 value가 분리되기 때문에 재사용이 가능합니다.
s6= pd.Series(np.arange(6),s5.index)
s6
반대로 values 값으로도 index처리가 가능합니다.
s7= pd.Series(np.arange(6),s6.values)
s7
Series의 특징을 살펴보았습니다. Series는 파이썬의 리스트 같으면서도 딕셔너리 같은 구조라는 걸 알고 가시면 될 것 같습니다. 이것으로 이번 포스팅을 마치겠습니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas]Series 슬라이싱 (0) | 2020.07.01 |
|---|---|
| [Pandas]Series drop, dropna (0) | 2020.06.28 |
| Series Boolean Select (0) | 2020.06.24 |
| Series 연산 (0) | 2020.06.20 |
| [Pandas] Series 간단 분석 (0) | 2020.06.16 |