[Pandas] 그룹화된 데이터프레임 필터링하기
- Python / Pandas
- 2022. 3. 7.
apply를 이용하면 그룹화한 데이터프레임에 lambda함수를 쓸 수 있었습니다. 그런데 람다함수로 부등식을 적용하게 되면 bool값으로 처리가 될 것이지만 True,False를 알려고 전처리를 하진 않습니다. 실제로 True,False를 반영하여 값이 걸러져 나와주어야 합니다.
그룹화된 데이터프레임을 True, False로 분류하였는데 이를 반영하려면 어떻게 해야할까요?
바로 filter() 를 쓰면 됩니다. 데이터프레임의 group화를 한 상태에서 그룹화된 데이터프레임마다 True와 False로 구분할 수 있는데 이를 데이터프레임에 반영해줍니다.
'Learning Pandas'의 예제를 가져오겠습니다.
import pandas as pd
import numpy as np
df = pd.DataFrame({'Label':list('AABCCC'),'Values':[1,2,3,4,np.nan,8]})
df
람다함수 만들기
filter에 앞서 람다함수를 이용한 True,False가 어떻게 나타나는지 apply를 통해 확인해보겠습니다.
f = lambda x: x.Values.count()>1
df.groupby('Label').apply(f)
apply를 적용하면 각 라벨별로 bool형식으로 나타나게 됩니다.
bool 값을 활용해 데이터프레임에 반영하여 나타나게 하기 위해 filter를 사용하게 됩니다.
filter 사용하기
2가지 예제를 보이겠습니다. 형식은 다 같습니다.
람다함수를 정의한 후 그룹화된 데이터프레임에 filter를 해주면 됩니다.
# 라벨 갯수 1보다 큰 경우만 출력
f = lambda x : x.Values.count()>1
df.groupby('Label').filter(f)
# NaN drop
f = lambda x: x.Values.isnull().sum()==0
df.groupby('Label').filter(f)
실제로 각 라벨별로 NaN 갯수합을 구해보면 다음과 같이 나옵니다.
for name, grouped in df.groupby('Label'):
print(grouped.Values.isnull().sum())C 라벨만 람다함수를 적용하면 False라서 필터링 되었습니다.
평균 filter
filter를 쓰려면 라벨별로 값을 찾는 건지 라벨 안에 각각의 값으로 값을 찾는지 명확히 해야합니다.
grouped = df.groupby('Label')
# 전체평균
mean = grouped.mean().mean()
# 라벨별 평균-전체평균
f = lambda x : abs(x.Values.mean()-mean)>2.0
df.groupby('Label').filter(f)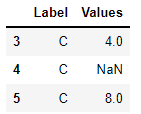
라벨별 평균에서 전체평균을 빼고 그 값에서 2.0 이 큰 경우에만 출력하도록 요청을 했습니다.
보시는바와 같이 C 라벨의 값만 나왔습니다. 이는 C 라벨의 각 값을 얘기하는게 아니라 C라벨이 전체평균에 2보다 크다는 것을 의미합니다.
실제로 각 라벨별로 평균을 구해보면 다음과 같습니다.
for name,grouped in df.groupby('Label'):
print(grouped.Values.mean())
전체평균은 3.5가 나오는데 6-3.5>2 이므로 C라벨만 해당되게 됩니다. filter가 잘 되었습니다.
만약 나오게 하고 싶은 값이 각 라벨의 평균이라면 agg로 평균만 표시한 후 filter를 진행합니다. 약간 복잡합니다.
grouped=df.groupby('Label')
ex = grouped.agg([np.mean])
ex_grouped=ex.groupby('Label')
mean = ex_grouped.mean().mean()
f = lambda x : abs(x-mean)>2.0
ex_grouped.filter(f)
filter 후 생략된 값 확인하기
어떤 값이 생략됐는지 확인하기 위한 방법입니다. 위에서 한 예 중에서 하나인 Values.count()>1 인 경우로 보겠습니다.
df에는 B의 값 갯수가 1개이므로 filter 처리를 하면 위에서 보인것처럼 생략되어 됩니다.
그런데 dropna=False 를 적용하면 없어져야 할 B를 가지고 옵니다.
하지만 B 는 NaN으로 처리되어 나타납니다.
f = lambda x: x.Values.count()>1
df.groupby('Label').filter(f,dropna=False)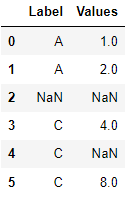
마치며
filter를 사용하면 람다함수로 이루어진 부등식을 그룹화된 데이터프레임에 쓸 수 있었습니다.
라벨링이 잘 되어 그룹화가 가능하다면 언제든지 부등식을 한꺼번에 적용할 수 있어 편리하게 데이터전처리를 할 수 있을겁니다.
관련 포스팅
[Pandas] 같은 범주로 묶기(groupby)
'Python > Pandas' 카테고리의 다른 글
| pandas plot (0) | 2022.03.10 |
|---|---|
| [Pandas]구간 나누기(pd.cut,pd.qcut) (0) | 2022.03.08 |
| [Pandas] groupby 데이터프레임에 함수 적용하기(transform) (0) | 2022.03.03 |
| [Pandas] 데이터프레임 재구조화(Melt) (0) | 2022.02.28 |
| [Pandas] 특수문자 제거하기 (0) | 2022.02.24 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!