[Pandas] 데이터프레임 재구조화(Melt)
- Python/Pandas
- 2022. 2. 28.
파이썬에서는 판다스로 주로 데이터 전처리를 합니다.
판다스에서 데이터 전처리의 중요한 요소인 재구조화(reshaping) 방법에는 pivot과 stack, unstack이 있고 melt라는 것도 있습니다.
앞선 포스팅에서 pivot,stack, unstack을 다뤘었고
이번 포스팅에서는 자주 쓰이는 재구조화 방법인 melt에 대해 알아보겠습니다.
melt은 한번에 보기 편하게 특정 컬럼을 기준으로 특정 값을 정렬한다는 보면 됩니다.
id에 해당하는 value_var를 선정해 variable 컬럼에 나열하여 value를 보여주는 형식입니다.
말로 설명하기가 참 어려운데 그림을 참고해주시기 바랍니다.
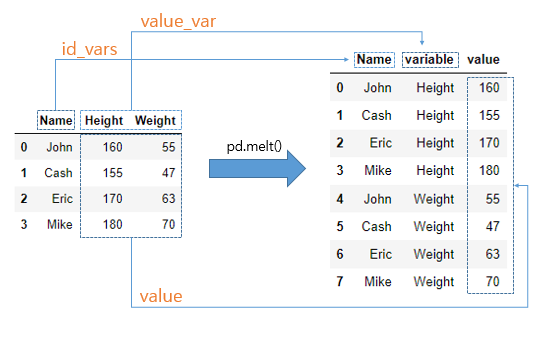
Melt
melt는 다음과 같은 파라미터를 가집니다.
pd.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
- frame : melt를 할 데이터프레임 지정
- id_vars : identity variables로 쓸 컬럼 지정(다수 가능), list or tuple 형식
- value_vars : unpivot할 컬럼 지정, None이면 id_vars를 뺀 나머지 컬럼으로 자동 지정
- var_name : value_var를 대표하는 이름 지정, None이면 variable을 이름으로 함
- value_name : value값 이름 지정 , None 이면 value로 지정됨
- col_level : 컬럼이 멀티컬럼으로 설정되어 있는경우 melt 할 레벨 지정
- ignore_index : 기존 인덱스 무시할것인가 여부. 디폴트는 True
- True : 인덱스 값 무시
- False : 기존 인덱스 적용
예제를 통해 살펴보겠습니다.
예제에 쓰는 데이터프레임은 Learning Pandas(pacty publishing) 라는 책에 나오는 예제를 변형했습니다.
data = pd.DataFrame({'Name':['John','Cash','Eric','Mike',],'Height':[160,155,170,180],'Weight':[55,47,63,70]})
기본 melt
id_vars만 설정해주면 알아서 melt를 시행합니다.
디폴트값대로 id_vars 에 해당되지 않은 컬럼은 모두 variable로 가고 그에 맞는 value 값 들어가고 기존 인덱스는 무시되서 새로운 인덱스가 생성되었습니다.
pd.melt(data,id_vars=['Name'])
id_vars 두개 이상일때
pd.melt(data,id_vars=['Name','Height'])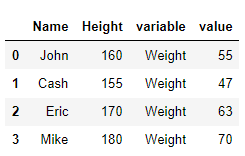
Name과 Hieght가 나란히 나왔습니다. 컬럼이 id_vars에 있어야 하는지 아닌지를 잘 판단해야 합니다.
이름 바꾸기
variable 은 Status로
value는 Body로 바꿔보았습니다.
pd.melt(data,id_vars=['Name'],var_name='Status',value_name='Body')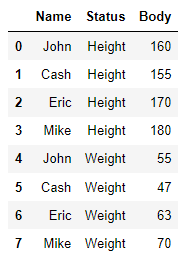
필요한 값만 가져오기
variable에 넣을 컬럼을 지정하려면 value_vars에 리스트 또는 튜플 형식으로 넣으면 됩니다.
pd.melt(data,id_vars=['Name'],value_vars=['Height'])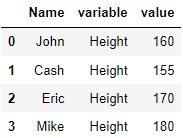
멀티컬럼 다루기
다음과 같은 데이터가 있을 때 melt를 실행해보겠습니다.
multi_data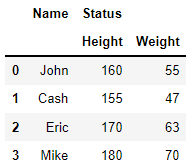
기본적으로 하면 다음과 같이 col_level에 따라 분류가 되어서 나옵니다.
pd.melt(multi_data,id_vars=['Name'])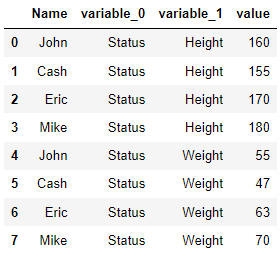
col_level을 분리하려면 같은 col_level에서만 실행할 수 있습니다.
즉, col_level이 같은 컬럼에서만 melt 작업을 할 수 있습니다.
pd.melt(multi_data,id_vars=['Name'],col_level=0)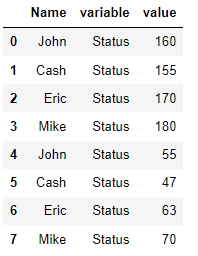
현재 Name은 col_level=0에만 있으므로 col_level=1에서 Name으로 melt를 실행하면 오류가 발생합니다.
pd.melt(multi_data,id_vars=['Name'],col_level=1)
따라서 Name을 col_level과 상관없이 id_vars를 쓰고 싶다면 모든 col_level에 Name이 지정되어 있어야 합니다.
multi_data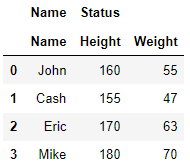
pd.melt(multi_data,id_vars=['Name'],col_level=1)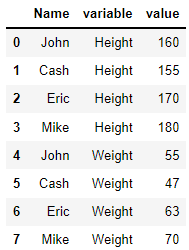
마치며
melt에 대한 사용법을 알아보았습니다. melt에 적합한 데이터프레임에 적용한다면 여러모로 유용할 것 같습니다.
이밖에도 pivot, stack, unstack 방법도 있으니 관련 포스팅을 참고해주시기 바랍니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 그룹화된 데이터프레임 필터링하기 (0) | 2022.03.07 |
|---|---|
| [Pandas] groupby 데이터프레임에 함수 적용하기(transform) (0) | 2022.03.03 |
| [Pandas] 특수문자 제거하기 (0) | 2022.02.24 |
| [Pandas] 데이터프레임 재구조화하기(Stack,Unstack) (0) | 2022.02.22 |
| [Pandas] 데이터프레임 행(row) 추가하기 (4) | 2022.02.10 |