데이터프레임의 apply로 람다함수를 적용할 수 있다는 것을 이전 포스팅에서 다루어보았는데 transform 메쏘드로 groupby 처리를 한 그룹화된 데이터프레임에 apply 처리를 하겠습니다.
그룹화되지 않은 데이터프레임에서는 apply를 적용을 했지만
그룹화된 데이터프레임에서는 apply와는 다른 것들을 할 수 있습니다.
즉, apply 대체로써 쓰는 것이 아니라 transform 만의 영역이 있습니다.
그 이유는 람다함수의 대상으로 쓰는 x의 단위로 볼 수 있는데 apply의 x는 행이나 열을 가르키고 transform에서의 x는 그룹화된 데이터프레임을 가르킵니다. 행이나 열에서 할 수 있는게 있고 데이터프레임을 대상으로 할 수 있는 게 다르기 때문에transform 만으로 할 수 있는 기능들을 극대화해서 쓸 필요가 있겠습니다.
파라미터는 다음과 같습니다.
DataFrame.transform(func, axis=0, args, *kwargs)
- func : 함수 넣기. 람다함수나 미리 만들어둔 함수 모두 가능
- axis : 축 설정
- 0: 각 컬럼에 적용
- 1: 각 로우에 적용
NaN 처리
NaN은 데이터프레임에서 fillna로 처리할 수 있습니다.
그런데 그룹화를 할 수 있는 것이라면 약간 달라집니다.
데이터프레임의 경우 fillna로 채울수 있는 방법은 NaN의 앞,뒤 값, 보간법, 지정 숫자정도인데 분포가 다른 두 집단을 합쳐놓은 데이터프레임에서 fillna를 시행한다면 어울리지 않는 값을 넣을 수 있습니다.
이런 경우 groupby를 통해 그룹화를 한 후 fillna를 한다면 좀 더 분포에 어울리는 값을 넣을 수 있습니다.
가장 NaN을 효과적으로 보여준 것 같아서 제가 공부했던 책인 Learning Pandas에서의 예제를 가져오겠습니다.
import pandas as pd
import numpy as np
df = pd.DataFrame({ 'Label': list("ABABAB"),
'Values': [10, 20, 11, np.nan, 12, 22]},
index=['1', '2', '3', '4', '5', '6'])
df 를 보면 A,B 그룹으로 나눠져 있고 B의 값 중에는 NaN이 있습니다.
이 상태에서 fillna를 한다면 11이나 12 또는 지정숫자가 되는 상황입니다. B군은 20근방의 숫자라서 앞뒤값을 가져오는건 큰 의미가 없습니다.
따라서 NaN을 의미있게 채우려면 B군에서의 값을 모아놓은 후 fillna를 하는 것이 바람직해보입니다. 이런 경우 transform으로 값을 채워넣을 수 있습니다.
먼저 Label을 기준으로 groupby를 실행하면 다음과 같이 나옵니다.
grouped = df.groupby('Label')
for name,group in grouped:
print(name)
print(group)이제 transform을 이용해 그룹의 평균을 NaN에 대신 넣겠습니다.
평균은 다음과 같습니다.
grouped.mean()
평균을 넣겠습니다.
filled_nan=grouped.transform(lambda x : x.fillna(x.mean()))
transform의 단점이라면 해당값에 컬럼만 나온다는 단점이 있습니다만 아마 개선되지 않을까 싶습니다. 어쨋든 df에 다시 넣기 위해서 filled_nan을 Values값에 넣어줍니다.
df.Values =filled_nan
df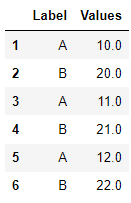
시계열 데이터 정규분포 표준화하기
시계열 데이터를 가지고 정규분포화 하는 경우가 많은데 이를 표준화하는 방법에도 transform을 쓸 수 있습니다.
주식데이터가 정규분포에 잘 맞진 않지만 삼성전자의 2019~2021년 종가가격데이터를 가지고 표준화를 해보겠습니다.
sam_close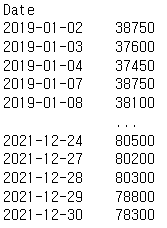
sam_close.plot()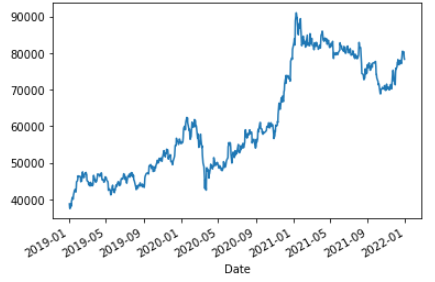
3년동안 지속적으로 올라가는 그림입니다. 년도별 평균과 표준편차를 보면 다음과 같습니다.
year_group = lambda x: x.year
groups = sam_close.groupby(year_group)
groups.agg([np.mean,np.std])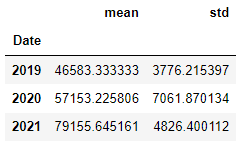
표준화식은 다음과 같습니다. 평균은 m, 표준편차는 σ 라 할때,
z=x−mσ
입니다. 표준화가 되면 평균은 0, 표준편차는 1이 되는 정규분포가 됩니다. 바로 적용을 하겠습니다.
zscore = lambda x: (x-x.mean())/x.std()
z_dis = groups.transform(zscore)
z_dis.groupby(year_group).agg([np.mean,np.std])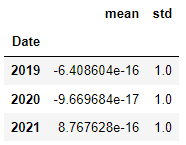
평균과 표준편차를 구해보니 0과 1이 되었습니다.
그림으로 보면 다음과 같습니다.
z_dis.plot()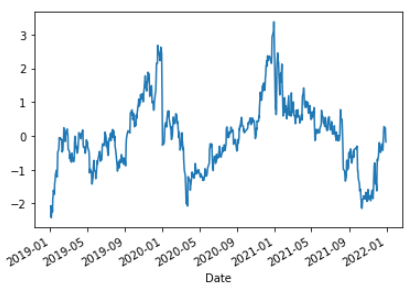
마치며
transform을 이용한 방법을 알아보았는데요. 저는 쉬운 예제만 보였는데 자신이 응용하고자 하면 얼마든지 위 예제보다 더 복잡한 데이터를 세련되게 표현할 수 있지 않을까 싶습니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas]구간 나누기(pd.cut,pd.qcut) (0) | 2022.03.08 |
|---|---|
| [Pandas] 그룹화된 데이터프레임 필터링하기 (0) | 2022.03.07 |
| [Pandas] 데이터프레임 재구조화(Melt) (0) | 2022.02.28 |
| [Pandas] 특수문자 제거하기 (0) | 2022.02.24 |
| [Pandas] 데이터프레임 재구조화하기(Stack,Unstack) (0) | 2022.02.22 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!