[Pandas]구간 나누기(pd.cut,pd.qcut)
- Python/Pandas
- 2022. 3. 8.
판다스에는 구간 나누는 기능이 있습니다. 그래서 카테고리를 만들 때 굉장히 편합니다.
물론 파이썬 자체에서도 가능하지만 제 생각에는 판다스로 하는게 편리하고 한눈에 볼 수 있어서 좋은 것 같습니다.
구간의 길이를 같게 할 것인지 구간안의 갯수를 같게 할 것인지 정하는 방법에 따라 구간을 나눌 수 있는데 판다스에서는 이 두개를 모두 할 수 있습니다.
구간 (-1,1) 사이의 숫자를 가지고 구간 나누기를 해보겠습니다.
import pandas as pd
import numpy as np
np.random.seed(122)
normal = np.random.normal(size=10000)
normal
같은 길이로 구간 나누기(pd.cut)
pd.cut을 이용하면 같은 길이로 구간을 나눌 수 있습니다.
값이 float일때
5개로 나눠보겠습니다.
pd.cut은 값이 float 형식일 때 모든 값이 포함할 수 있도록 최소값-extra, 최대값+extra로 구간을 나눕니다. 여기서 extra=(최대값-최소값)0.1% 입니다.
*(무한에 가까운 소수가 나오는 경우 확실하게 포함시키기 위함입니다)
bins = pd.cut(normal,5)
bins
카테고리만 보면 다음과 같이 나옵니다.
bins.categories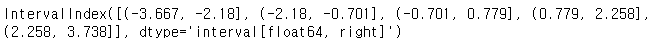
전체정보를 보려면 describe() 로 할 수 있습니다.
bins.describe()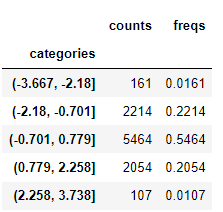
직접 나누어서 실제로 bins처럼 되는지 살펴보겠습니다.
최소값과 최대값의 차이를 5개로 나눠 그 크기로 잘라줍니다.
np.arrange를 이용해 구간을 나누려고 하는데 반드시 처음값을 최소값으로 시작해야 합니다. 최소값-extra로 하면 최대값이 포함되지 않게 됩니다.
min = normal.min()
max = normal.max()
delta = max-min
size = delta/5
extra= delta*0.001
intervals = np.arange(min,max+extra,size)
#min-extra
intervals[0] -= delta*0.001
intervals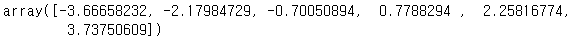
pd.cut과 비슷하게 구간 나누기가 된 것을 볼 수 있습니다.
값이 int일 때
값이 int라도 구간 나누기가 가능합니다.
나이를 나타내는 임의의 숫자를 만들겠습니다.
np.random.seed(122)
ages = np.random.randint(6,45,50)
ages
어린이, 청소년, 청년, 중년으로 나누기 위해 다음과 같이 나누겠습니다.
ranges=[5,12,18,35,50]
age_bins = pd.cut(ages,ranges)
age_
bins.describe()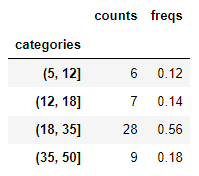
위의 그림은 카테고리를 구간으로 표시되어 있습니다.
라벨링을 하면 더 좋을 것 같습니다.
구간이 아닌 라벨을 붙이려면 label을 리스트형식으로 만들어서 cut의 labels 파라미터에 넣습니다.
labels = ['어린이','청소년','청년','중년']
age_bins = pd.cut(ages,ranges,labels=labels)
age_bins.describe()
같은 갯수로 구간 나누기(pd.qcut)
이번에는 같은 갯수로 구간을 나누어 보겠습니다.
위에서 예제로 쓴 normal을 그대로 가져오겠습니다.
normal은 만개의 숫자로 이루어져 있으므로 pd.qcut으로 5개로 구간을 나눈다면 2000개씩 자르게 될 것입니다.
same_count_bin = pd.qcut(normal,5)
same_count_bin.describe()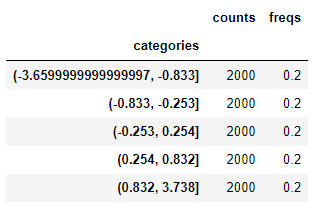
정규분포로 나눌경우는 count가 달라지고 정규분포에 따라 움직입니다. 신뢰구간 구하는 경우 표준편차의 $ \pm 1,2,3 $으로 나눌 수 있는데 이를 한번 적용해보겠습니다.

그림출처 Dan Kernler via Wikipedia Commons:
https://commons.wikimedia.org/wiki/File:Empirical_Rule.PNG
{kind=link}
std = [0,0.001,0.021,0.5-0.341,0.5,0.5+0.341,1.0-0.021,1.0-0.001,1.0]
qbin = pd.qcut(normal,std)
qbin.describe()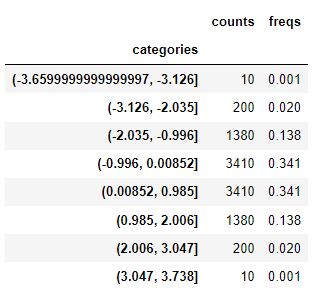
count가 맞춰지는게 아니라 freqs 로 맞춰지는걸 볼 수 있습니다.
참고로 이게 되는 이유는 현재 데이터가 정규분포라서 가능한겁니다.
정규분포가 아닌경우에는 freqs로 맞춰지지 않습니다.
마치며
데이터프레임을 가지고 구간 나누는 두가지 방법에 대해 알아보았습니다.
cut나 qcut으로 어렵지 않게 구간을 나눌 수 있고 describe()를 이용해 간편하게 볼 수 있다는 장점이 있었습니다. 자신의 상황에 맞게 쓰면 아주 유용할 것 같습니다.
관련 포스팅
ndarray 생성하기
참고문헌
Learning pandas/Michael Heydt/pacty
그림출처
Dan Kernler via Wikipedia Commons: https://commons.wikimedia.org/wiki/File:Empirical_Rule.PNG
'Python > Pandas' 카테고리의 다른 글
| pandas로 bar,hist,density 그리기 (0) | 2022.03.15 |
|---|---|
| pandas plot (0) | 2022.03.10 |
| [Pandas] 그룹화된 데이터프레임 필터링하기 (0) | 2022.03.07 |
| [Pandas] groupby 데이터프레임에 함수 적용하기(transform) (0) | 2022.03.03 |
| [Pandas] 데이터프레임 재구조화(Melt) (0) | 2022.02.28 |