iris dataset 가져오기(데이터셋 가져오는 요령)
- 데이터 사이언스 / 머신러닝 딮러닝
- 2023. 1. 14.
분류 문제 실습용으로 가장 좋은 iris dataset 가져오는 방법입니다.
여러 방법이 있지만 머신러닝에서 가장 선호하는 건 sklearn을 이용한 방법이 아닐까 싶습니다. 주요 데이터셋은 sklearn에 내장되어있기 때문에 손쉽게 데이터를 받을 수 있습니다.
Iris 데이터셋 가져오기
다음과 같이 합니다.
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
Iris = load_iris()
Iris
Iris를 불러보면 다음과 같이 딕셔너리로 구성되어있습니다. 밑에 가보면 데이터 정보도 같이 줍니다.
딕셔너리 그대로 머신러닝을 돌리기에는 무리가 있습니다. 데이터 정보를 토대로 데이터프레임에 옮겨보겠습니다.
'data'에는 4개의 컬럼으로 이루어져 있는데 각 columns 은
'feature_names': ['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)'] 으로 구성되어있다고 합니다.
이에 맞게 데이터프레임을 구성해줍니다.
딕셔너리에 이미 feature_names로 데이터 저장이 되어있으니 손쉽게 columns을 만들 수 있습니다.
또한, target 값은 라벨링한 값이므로 머시러닝에서는 y값에 해당합니다. 분리를 해놓습니다.
Iris_Data = pd.DataFrame(data=Iris['data'], columns= Iris['feature_names'])
Iris_target = pd.DataFrame(data=Iris['target'],columns = ['target'])
target 분류 카테고리 정리
데이터 정보를 더 보면 target의 분류카테고리는 다음과 같다고 합니다.
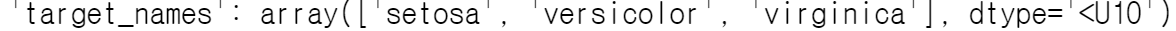
머신러닝으로 데이터분석할 때는 필요는 없지만 추후 플롯을 넣고 보고서를 작성할 때는 카테고리 값으로 다시 변경하는 게 좋습니다. replace를 이용해 직접 값을 넣어서 target을 변경해도 되고 딕셔너리 값을 활용해 간편하게 해도 좋습니다.
Iris_target.replace([0,1,2],Iris['target_names'],inplace=True)
기존 값을 보존하고 싶다면 inplace =False로 한 후 재정의 합니다.
Iris_target_name = Iris_target.replace([0,1,2],Iris['target_names'],inplace=True)
마치며
실습 데이터셋은 iris 와 비슷하게 동작합니다.
데이터셋을 처음 받으면 약간 당황할 수 있는데 잘 살펴서 자신이 필요한 것만 추출해서 머신러닝이나 딮러닝 실행을 시작하면 됩니다.
'데이터 사이언스 > 머신러닝 딮러닝' 카테고리의 다른 글
| 머신러닝이란? (0) | 2023.06.26 |
|---|---|
| [자연어처리] NLTK 설치 및 소개 (0) | 2023.05.15 |
| [머신러닝] 지도학습 성능 평가방법 총정리 (0) | 2022.12.05 |
| [우분투] 파이토치 설치 쉽게하기 (0) | 2022.09.06 |
| 선형회귀(Linear regression) (0) | 2021.12.20 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!