[자연어처리] NLTK 설치 및 소개
- 데이터 사이언스/머신러닝 딮러닝
- 2023. 5. 15.
요즘은 어떤지 모르겠지만 저는 개인적으로 자연어 맨처음 시작할 때 공부용으로 쓰던 NLTK입니다. 한글지원은 약하고 주로 영어를 사용합니다. 이미 생성AI가 나오는 판국에 이제와서 무슨 자연어 처리일까 싶겠지만 인공지능은 데이터기반으로 하기 때문에 내가 데이터만 잘 가져온다면 어디서든 새로운 걸 만들어낼 수 있습니다. 모두가 구글 될게 아니기 때문에 자신의 주변에서 필요한 부분이 분명 있을테니 영감을 얻는 도구로써 한번 체험해보시길 바랍니다.
NLTK 소개
NLTK(Natural Language Toolkit)은 파이썬에서 자연어 처리를 수행하기 위한 라이브러리입니다. 텍스트 데이터 분석, 토큰화, 형태소 분석, 품사 태깅, 문장 구문 분석 등 다양한 자연어 처리 작업을 지원하며, 학술 연구부터 실제 응용까지 다양한 분야에서 활용되고 있습니다. 요즘은 ChatGPT로 생성 AI가 나왔지만 자연어 처리를 배우길 원하신다면 입문용으로 쓰기 좋습니다.
NLTK의 주요 기능
NLTK는 다음과 같은 주요 기능은 다음과 같습니다.
텍스트 데이터 처리: NLTK는 텍스트 데이터를 불러오고, 전처리하는데 유용한 기능을 제공합니다. 텍스트 데이터의 읽기, 쓰기, 수정 등을 쉽게 처리할 수 있습니다.
토큰화(Tokenization): NLTK는 텍스트를 단어나 문장으로 분리하는 토큰화 작업을 수행할 수 있습니다. 이를 통해 텍스트 데이터를 의미있는 단위로 분석할 수 있습니다.
형태소 분석(Morphological Analysis): NLTK는 단어를 형태소 단위로 분석하는 기능을 제공합니다. 이를 통해 단어의 원형 복원, 품사 태깅 등을 수행할 수 있습니다.
품사 태깅(Part-of-Speech Tagging): NLTK는 단어에 대해 품사 정보를 부착하는 작업을 수행할 수 있습니다. 이를 통해 문장의 구조와 의미를 분석할 수 있습니다.
문장 구문 분석(Syntactic Parsing): NLTK는 문장의 구조를 분석하여 구문 트리를 생성하고, 문장의 의미와 구조를 이해하는데 도움을 줍니다.
NLTK의 활용 분야
자연어 처리 연구: 자연어 처리 연구에 많이 사용되며, 언어 모델링, 기계 번역, 감성 분석 등 다양한 연구 주제에 적용됩니다.
정보 검색 및 텍스트 마이닝: 검색 엔진, 텍스트 분석 및 정보 추출과 같은 텍스트 기반 애플리케이션에 활용됩니다.
챗봇 및 인공지능 어시스턴트: 챗봇 및 인공지능 어시스턴트 개발에 사용되어 자연어 이해와 자연어 생성에 도움을 줍니다.
교육 및 학습: 자연어 처리를 가르치기 위한 교육용 도구로도 활용됩니다. NLTK는 학습자들에게 자연어 처리의 기초를 이해하고 실습할 수 있도록 내장 데이터를 가지고 있어서 별도 설치없이 자연어를 공부하기 굉장히 좋습니다.
어플리케이션 개발: 텍스트 데이터를 처리해야 하는 다양한 어플리케이션 개발에 사용됩니다. 텍스트 분석을 통한 감성 분석, 키워드 추출, 자동 요약 등의 기능을 구현할 때 활용할 수 있습니다.
NLTK 설치하기
NLTK(Natural Language Toolkit)를 사용하기 위해서는 먼저 NLTK를 설치해야 합니다.
아나콘다를 설치하신 분들은 별도 설치가 필요없고 패키지로 설치하지 않고 단독으로 파이썬을 설치하거나 미니콘다로 하신다면 설치를 해야합니다.
pip install nltk- NLTK 데이터셋 다운로드
NLTK는 자연어 처리를 작업에 필요한 리소스와 샘플 데이터를 제공합니다. 이런 데이터셋을 사용하려면 추가적인 다운로드가 필요합니다.
import nltk
nltk.download()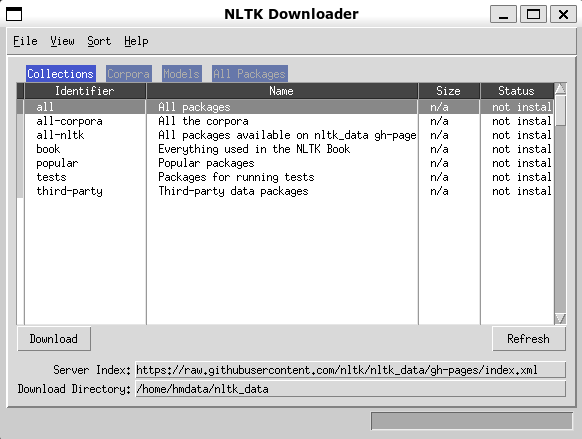
위 코드를 실행하면 NLTK 데이터셋 다운로드 관리자가 실행됩니다. 다운로드 관리자에서는 필요한 데이터셋이나 리소스를 선택하여 다운로드할 수 있습니다. 필요한 데이터셋을 선택하고 "Download" 버튼을 클릭하여 다운로드를 진행합니다. 공부가 목적이라면 모두 설치하는 것을 추천합니다. 이것저것 해보는 게 확실히 도움이 되긴 한 것 같습니다.
NLTK 사용 예제
간단한 예제를 소개하겠습니다.
텍스트 데이터 불러오기 및 전처리
NLTK를 사용하여 텍스트 데이터를 불러오고 전처리하는 과정이 자연어 처리 작업의 첫 단계라고 할 수 있습니다. NLTK는 텍스트 파일이나 웹 페이지 등에서 데이터를 추출할 수 있는데요. 텍스트 파일에서 데이터를 불러와보겠습니다.
import nltk
# 텍스트 파일에서 데이터 불러오기
with open('data.txt', 'r') as file:
text = file.read()
# 텍스트 전처리
text = text.lower() # 소문자 변환
text = nltk.sent_tokenize(text) # 문장 토큰화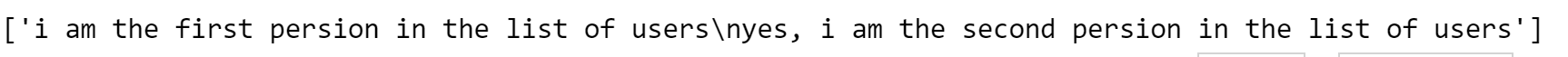
두문장을 해봤는데 문장구분이 완벽하진 않지만 잘해긴 합니다. /n 에 대한 부분은 문자열로 해결할 수 있으니 아쉽지만 된다는 건 확인했습니다.
토큰화(Tokenization)
토큰화는 텍스트를 단어나 문장으로 분리하는 작업입니다. 이번에는 문자열로 진행해보겠습니다.
import nltk
text = "This is a sample sentence."
# 단어 토큰화
tokens = nltk.word_tokenize(text)
print(tokens) # ['This', 'is', 'a', 'sample', 'sentence', '.']
# 문장 토큰화
sentences = nltk.sent_tokenize(text)
print(sentences) # ['This is a sample sentence.']
형태소 분석(Morphological Analysis)
형태소 분석은 단어를 형태소 단위로 분석하는 작업입니다.
import nltk
text = "I want to eat an apple."
# 형태소 분석기 초기화
tokenizer = nltk.tokenize.ToktokTokenizer()
morph_analyzer = nltk.stem.WordNetLemmatizer()
# 단어 토큰화 및 형태소 분석
tokens = tokenizer.tokenize(text)
lemmas = [morph_analyzer.lemmatize(token) for token in tokens]
print(lemmas) # ['I', 'want', 'to', 'eat', 'an', 'apple', '.']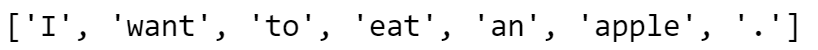
품사 태깅(Part-of-Speech Tagging)
품사 태깅은 단어에 품사 정보를 부착하는 작업입니다.
import nltk
sentence = "NLTK is a powerful tool for natural language processing."
# 문장을 단어로 토큰화
tokens = nltk.word_tokenize(sentence)
# 토큰에 대한 품사 태깅
tagged_tokens = nltk.pos_tag(tokens)
print(tagged_tokens)
결과는 토큰화된 단어와 해당 단어의 품사 태그로 이루어진 튜플들의 리스트로 반환됩니다. 각 단어와 그에 대응하는 품사 태그가 튜플로 묶여 리스트 형태로 출력됩니다. 위 예제를 통해 NLTK를 사용하여 영문 문장을 품사별로 태깅할 수 있는 방법을 알 수 있습니다.
NLTK 확장 기능과 플러그인
좀 더 NLTK를 잘 쓰기 위해서는 확장 기능과 플러그인이 필요합니다. NLTK의 기능을 확장하고 개선하여 더 다양한 자연어 처리 작업을 할 수 있게 됩니다. 저도 다 아는게 아니라서 대표적인 확장 플러그인 몇개만 소개합니다.
WordNet
WordNet은 영어의 시소러스(유의어 사전)로서 NLTK의 WordNet 패키지를 통해 활용할 수 있습니다. WordNet은 단어들 사이의 상위어, 하위어, 유의어 등의 관계를 제공하여 단어의 의미를 이해하는데 도움을 줍니다. 다음은 WordNet을 사용하여 유의어를 찾는 예제입니다:
from nltk.corpus import wordnet
# 단어의 유의어 찾기
synonyms = []
for syn in wordnet.synsets("happy"):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms) # ['happy', 'felicitous', 'glad', 'happy', 'well-chosen', 'happy', 'well-situated', 'proud']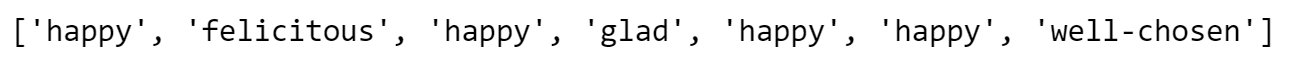
Vader 감성 분석기
NLTK는 감성 분석을 수행하는 Vader라는 감성 분석기를 제공합니다. Vader는 텍스트의 감정 성향을 분석하여 긍정적인지, 부정적인지, 중립적인지를 판단하는데 사용합니다. 썸트렌드라는 사이트를 가보면 키워드에 대한 감정분석을 해주는데요. 서로 비교하시면 좋을 것 같습니다.
from nltk.sentiment import SentimentIntensityAnalyzer
text = "I love this movie! It's so amazing."
analyzer = SentimentIntensityAnalyzer()
sentiment = analyzer.polarity_scores(text)
print(sentiment)
# {'neg': 0.0, 'neu': 0.179, 'pos': 0.821, 'compound': 0.8779}
Vader는 텍스트의 긍정, 부정, 중립, 강도를 나타내는 네 가지 지표를 제공합니다.
Brill 태거
Brill 태거는 품사 태깅을 수행하는데 사용되는 ML(Machine Learning) 기반의 태깅 알고리즘입니다. Brill 태거는 학습 데이터를 기반으로 품사 태깅을 수행하며, 정확도가 높은 태깅 결과를 제공합니다.
import nltk
from nltk.tag import brill, brill_trainer
# 훈련 데이터셋 준비 (예제로 간단한 데이터 사용)
train_data = [
[('I', 'NN'), ('am', 'VBP'), ('learning', 'VBG'), ('NLTK', 'NN')],
[('NLTK', 'NN'), ('is', 'VBZ'), ('a', 'DT'), ('powerful', 'JJ'), ('tool', 'NN')],
[('It', 'PRP'), ('is', 'VBZ'), ('used', 'VBN'), ('for', 'IN'), ('natural', 'JJ'), ('language', 'NN'), ('processing', 'NN')],
]
# 훈련을 위해 태그된 문장 데이터 생성
tagged_sentences = [sentence for sentence in train_data]
# Brill 태거 훈련
templates = brill.brill24()
initial_tagger = nltk.DefaultTagger('NN')
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger=initial_tagger, templates=templates)
brill_tagger = trainer.train(tagged_sentences)
# 품사 태깅 예제 문장
sentence = "I love using NLTK for natural language processing."
# 문장을 단어로 토큰화
tokens = nltk.tokenize.word_tokenize(sentence)
# 품사 태깅
tagged_sentence = brill_tagger.tag(tokens)
print(tagged_sentence)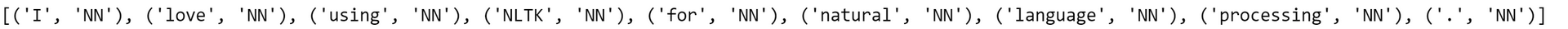
위 예제에서는 간단한 훈련 데이터셋을 사용하여 Brill 태거를 훈련하고, 이를 활용하여 새로운 문장에 대한 품사 태깅을 수행합니다. brill.brill24() 함수는 Brill 태거에 사용할 변환 템플릿을 설정합니다. 훈련 데이터셋은 리스트 형태로 구성되어 있으며, 문장 내 단어와 품사를 튜플로 묶은 형태로 저장됩니다.
마치며
NLTK는 자연어 처리 도구로써 다양한 작업을 수행할 수 있으며, 커뮤니티의 지원과 다양한 자원을 통해 자연어 처리에 대한 지식과 기술을 확장할 수 있습니다. 입문하기에도 좋고 여기저기서 쉽게 자료를 찾아볼 수 있으니 자연어를 공부하겠다면 꼭 활용해보시기 바랍니다.
참고 자료
NLTK 공식 홈페이지: NLTK의 공식 홈페이지에서 문서, 예제, 자료 등을 찾아볼 수 있습니다.
NLTK :: Natural Language Toolkit
Natural Language Toolkit NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries
www.nltk.org
NLTK Cookbook: NLTK Cookbook은 실용적인 예제와 함께 NLTK의 다양한 기능과 활용법을 설명합니다.
Natural Language Processing with Python: 이 책은 NLTK를 활용하여 자연어 처리 작업을 수행하는 방법을 자세히 설명하고 있습니다.
자연어 처리와 딥러닝 : 2021년 대한민국학술원 우수학술도서 선정도서로 선정되었는데 초보자에겐 좀 어렵지만 하나하나 설명을 해주어서 끈기있게 읽는다면 도움이 되지 않을까 싶습니다.



'데이터 사이언스 > 머신러닝 딮러닝' 카테고리의 다른 글
| [파이썬] 선형회귀 간단하게 구현 (0) | 2023.10.19 |
|---|---|
| 머신러닝이란? (0) | 2023.06.26 |
| iris dataset 가져오기(데이터셋 가져오는 요령) (0) | 2023.01.14 |
| [머신러닝] 지도학습 성능 평가방법 총정리 (0) | 2022.12.05 |
| [우분투] 파이토치 설치 쉽게하기 (0) | 2022.09.06 |