[머신러닝] MNIST를 이용한 다중분류기 구현기
- 데이터 사이언스 / 머신러닝 딮러닝
- 2021. 12. 11.
MNIST를 이용한 다중분류기 구현 방법입니다.
다중분류기는 여러 개의 클래스로 구별하기 위해서 만드는데 SGD, 랜덤 포레스트 ,나이브 베이즈 같은 분류기로 직접 처리가 가능합니다.
다중 분류기를 사용해 직접 사용하기 전에 이진 분류기인 서포트 벡터 머신 분류기를 이용해 다중 클래스로 분류하는 방법을 소개할까 합니다. 원리를 설명하기에 좋고 전략을 세워가는 재미(?)를 아시게 되지 않을까 싶습니다.
One-versus-the-rest(OvR)
OvR은 숫자 하나 대 나머지를 비교하는 전략입니다. One-versus-all(OvA)라고도 합니다.
숫자별로 숫자 하나만 구별하는 이진 분류기를 만들어서 점수를 매깁니다. 그럼 10개의 점수가 나오는데 이중에서 가장 높은 점수가 나오는 것을 선택하는 방식입니다.
MNIST 같은 경우 0~9 까지 10개 숫자가 있는데 10개의 숫자를 하나씩 뽑아서 다른 숫자와 구별하는 이진 분류기 10개를 만들어 각각의 점수를 매기는 작업을 하게 됩니다.
간단한 모델은 사이킷런에 OneVsRestClassifier 을 사용하면 구현할 수 있습니다.
#setting
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train_reshape = x_train.reshape([-1,28*28])
#OvR
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
ovr_clf = OneVsRestClassifier(SVC())
ovr_clf.fit(x_train_reshape,y_train)
ovr_clf.predict([x_train_reshape[35]])
One-versus-One(OvO)
OvO는 1대1로 이진분류기를 만드는 방법입니다.
MNIST로 예를 보면 10개의 숫자 하나와 숫자 하나를 매칭시켜 45개의 분류기(10개에서 2개를 뽑는 조합)를 만듭니다. 이미지 분류하기 위해 그림마다 45개의 분류기를 모두 통과시켜 양성이 가장 많은 클래스로 분류시키는 방법입니다.
작게 나눠서 훈련시키는 쪽이 유리한 알고리즘에 사용됩니다.
대부분은 OvR을 선호하기는 합니다.
from sklearn.multiclass import OneVsOneClassifier
ovo_clf = OneVsOneClassifier(SVC())
ovo_clf.fit(x_train_reshape,y_train)
ovo_clf.predict([x_train_reshape[35]])실제 분류기 갯수를 보면 45개로 되어있습니다.
len(ovo_clf.estimators_)
오차분석
이진분류기처럼 오차행렬을 구한후 분석을 합니다만 다중 클래스다 보니 단순히 숫자로 보는것은 어려울 수 있어
그림을 이용해 접근해나갑니다.
OvR 의 경우로 보겠습니다.
conf_mx = confusion_matrix(y_train,y_train_pred)
conf_mx
plt.matshow(conf_mx,cmap=plt.cm.gray)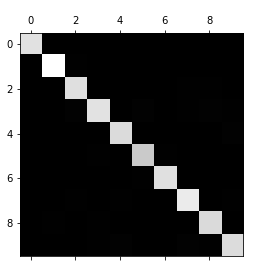
오차행렬을 보면 10x10의 행렬로 되어 있습니다. 대각행렬의 값이 크게 나오면 대체로 잘 나온 것으로 볼 수 있습니다.
그림으로 보면 중앙이 흰색이나 회색으로 된 그림이 나옵니다.
흰색으로 나올수록 값이 크다는 얘기입니다. 그렇다는 건 색이 어두울수록 상대적으로 분류를 못했다는 얘기입니다.
지금의 그림에서는 5가 유독 어둡습니다.
이는 숫자5에 대한 데이터셋이 적거나 분류기 성능이 안 좋은 경우입니다.
두 가지에 대해서 확인이 필요합니다.
일단 상대적인 에러비율을 보기 위해 열 전체를 하나씩 더해 오차행렬을 나누겠습니다.
이를 norm_conf_mx 라고 하겠습니다.
그림은 행은 실제 클래스를 나타내고 열이 예측한 클래스를 나타냅니다.
따라서 norm_conf_mx는 예측값이 좋을수록 값이 작아집니다.
그림으로 본다면 흰색이 될수록 흰색이 된 숫자로 잘못 분류했다는 얘기가 됩니다.
대각행렬은 정답이니 의미가 없어 0으로 처리하고 그림으로 반환합니다.
row_sums = conf_mx.sum(axis=1,keepdims=True)
norm_conf_mx = conf_mx/row_sums
np.fill_diagonal(norm_conf_mx,0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()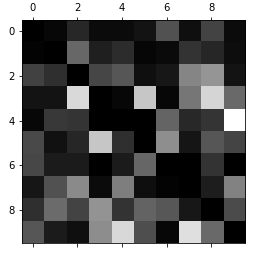
굉장히 정신없습니다. 분류가 제대로 안 되고 있다는 얘기입니다. 기본적인 OvR로 하고 아무런 조치를 안 생겨서 생긴 문제인 것 같습니다.
오차분석이 가능해야하니 개선한 케이스로 하겠습니다.
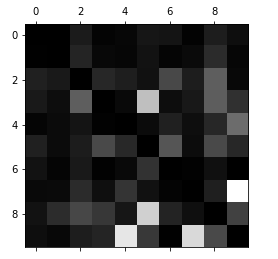
앞의 그림보다는 나은 그림인데 행이 실제 클래스고 열이 예측한 클래스라는 것을 기억하시면 됩니다.
열로 보면 흰색이 5와 9에서 나타났는데 5행을 보면 그리 나쁘지 않습니다.
그렇다는건 실제 5는 나쁘지 않게 배열이 되었음을 알 수 있습니다.
보통 3과 8로 혼동했다는 것을 해석할 수 있습니다.
9같은 경우는 실제도 잘 분류하지 못했고 예측도 엉망입니다만 한가지 알 수 있는 것은 9가 주로 4와 7에서 혼동이 오고 있다는 것을 알 수 있습니다.
제대로 한다면 훈련 데이터를 더 많이 모아서 훈련시키거나 분류기 모델을 개선할 수 있는 방향으로 갈 수도 있습니다.
아무튼 이렇게 그림으로 체크해서 분류기가 어떻게 일을 했는지 짐작해볼 수 있습니다.
3,8 숫자에서 5같은 것이 있는지 확인해보겠습니다.
def plot_digits(instances, images_per_row=10, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = mpl.cm.binary, **options)
plt.axis("off")
cl_a, cl_b = 3,8
X_aa = x_train_reshape[(y_train==cl_a) & (y_train_pred == cl_a)]
X_ab = x_train_reshape[(y_train==cl_a) & (y_train_pred == cl_b)]
X_ba = x_train_reshape[(y_train==cl_b) & (y_train_pred == cl_a)]
X_bb = x_train_reshape[(y_train==cl_b) & (y_train_pred == cl_b)]
plt.figure(figsize=(8,8))
plt.subplot(221); plot_digits(X_aa[:25],images_per_row=5)
plt.subplot(222); plot_digits(X_ab[:25],images_per_row=5)
plt.subplot(223); plot_digits(X_ba[:25],images_per_row=5)
plt.subplot(224); plot_digits(X_bb[:25],images_per_row=5)
plt.show()
3을 보면 5를 그리다 만것같은 그림이 1~2개 정도 있긴 하지만 사람의 눈이라면 모두 3으로 할만 한 것입니다.
8을 보면 5같이 보일 수 있을만한것이 있습니다.
8 같은 건 사람의 눈으로도 애매하게 판정할만한 것이 있네요.
이런식으로 알아보고 모델을 바꿀 것인지 파라미터를 변경해서 개선을 할것인지를 결정할 수 있습니다.
여기서는 당장 모델의 특성을 다 설명할 수 없으니 모델에 대한 특성은 추후에 하나씩 써내려가도록 하겠습니다.
긴 글 읽어주셔서 감사합니다. 도움이 되셨길 바랍니다^^
관련 포스팅
[데이터 사이언스/머신러닝 딮러닝] - [ML] 오차행렬
[데이터 사이언스/머신러닝 딮러닝] - [분류문제] MNIST로 이진분류기 만들기
'데이터 사이언스 > 머신러닝 딮러닝' 카테고리의 다른 글
| [우분투] 파이토치 설치 쉽게하기 (0) | 2022.09.06 |
|---|---|
| 선형회귀(Linear regression) (0) | 2021.12.20 |
| [머신러닝] 혼동행렬(Confusion matrix) (0) | 2021.12.07 |
| [분류문제] MNIST로 이진분류기 만들기 (0) | 2021.11.28 |
| [Python]회귀(3D plot) (0) | 2021.11.03 |




데이터목장님의
글이 좋았다면 응원을 보내주세요!