[머신러닝] 혼동행렬(Confusion matrix)
- 데이터 사이언스 / 머신러닝 딮러닝
- 2021. 12. 7.
이전 포스팅에서 MNIST에서 이진 분류기를 만들어 보았는데 글이 길어지다 보니
검증에 대한 개념을 위한 포스팅을 따로 합니다.
이진 분류기를 만드는 과정과 검증방법은 이전 포스팅에서 확인해주시기 바랍니다.
2021.11.28 - [데이터 사이언스/머신러닝 딮러닝] - [분류문제] MNIST로 이진분류기 만들기
[분류문제] MNIST로 이진분류기 만들기
머신러닝의 가장 기초중의 기초 머신러닝의 'Hello World' MNIST입니다. 머신러닝은 기본적으로 주어진 데이터를 가지고 컴퓨터를 훈련을 시키기 때문에 훈련,검증의 두단계를 거칩니다. 주어진 데
seong6496.tistory.com
혼동행렬은 약간 복잡합니다.
교차 검증을 통한 정확도를 하면 좋겠지만
분류기의 예측값과 정답과의 차이를 반영했는지와
데이터의 편중이 얼마나 되느냐에 따라 정확도가 많이 달라지게 됩니다.
실제로 교차검증을 이용해 정확도를 구하면 말이 안 되는 상황이 나옵니다.
성능 평가를 하는 지표 자체에 기복이 생기면 신뢰를 할 수 없어 분류기의 경우
단순한 교차검증의 정확도를 선호하지 않고 혼행렬을 주로 씁니다.
혼동행렬
분류기가 잘 되었는지 확인을 하기 위해서 생각해볼게 있습니다.
5를 분류하는 이진분류기를 예로 들겠습니다.
이진 분류기의 경우 실제 값과 예측 값 2개씩 존재하므로 4가지 경우가 생깁니다.
- TP(True positive) : 실제로 5이고, 예측도 5인경우 (진짜 양성)
- TN(True negative) : 실제로 5가 아니고, 예측도 5가 아닌 경우 (진짜 음성)
- FP(False positive) : 실제로 5가 아닌데, 예측은 5인 경우 (거짓 양성)
- FN(False negative) : 실제로 5인데, 예측은 5가 아닌 경우 (거짓 음성)
여기서 양성, 음성은 예측값에 의존하는데 양성은 예측값이 5가 맞다고 판단한 것이고 음성은 5가 아니라고 판단한 경우입니다.
진짜는 실제와 예측이 맞는 경우, 가짜는 실제와 예측이 틀린경우를 의미합니다.

4개의 경우가 존재하니 그에 맞게 검증을 해주어야 합니다.
위와 같이 4개의 경우를 고려해서 분류기의 성능을 평가하는 방법을 혼동행렬(Confusion Matrix)라고 합니다.
이를 파이썬으로 구현할 수 있는데 사이킷런의 confusion_matrix를 이용합니다.
그런데 위의 설명대로 한다면 실제 타깃과 비교할 수 있는 예측값이 존재해야 합니다.
따라서 cross_val_predict를 이용해 예측값을 가져옵니다.
# 교차검증 설정
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf,x_train_reshape,y_train_5,cv=3)
# 혼동행렬
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5,y_train_pred)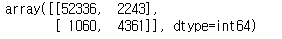
위와 같이 혼행렬을 구했습니다.
TN : 52336 , TP : 4361, FN : 1060, FP : 2243 으로 나왔습니다.
그럴 일은 거의 없지만 만약 완벽한 분류기라면 TP, TN 만 가지고 있으므로 대각행렬이 됩니다.
실제로는 구할 수 없는 행렬이므로 똑같은 데이터를 넣어서 살펴봤습니다.
이런 경우가 나온다면 만든 모델이 완벽 그 자체라는 의미라서 실질적으로 말이 안 되는 상태가 됩니다.
데이터를 잘 넣었는지 확인해보아야 합니다.
#완벽한 분류기인 경우
confusion_matrix(y_train_5,y_train_5)
혼행렬으로 분포를 알아보았다면 실제로 성능이 어떤지 살펴보아야 합니다.
따라서 위에서 구한 4개의 값으로 비율을 구합니다.
지표
양성예측의 정확도를 살펴보는 정밀도(precision) 입니다.
양성(P)에 대한 확률로 나타낼 수 있습니다.
precision=TPTP+FP
즉, 5를 분류하는 이진분류기로 예를 들면, 실제로 5로 분류가 맞는경우 / 5로 분류한 모든 것 이 되겠습니다.
하지만 다른 양성 샘플을 무시할 수 있기 때문에 정밀도 하나만으로는 부족합니다.
재현율이라는 지표과 함께 사용합니다.
분류기가 정확하게 감지한 양성 샘플의 비율로 재현율(recall) 이라고 합니다.
민감도(sensitivity), 진짜 양성 비율(TPR)이라고도 합니다.
재현율은 다음과 같습니다.
recall=TPTP+FN
정밀도는 양성표본의 실제 맞춘 양성에 초점을 맞췄고
재현율은 실제값의 갯수에서 분류기가 실제로 얼마나 맞췄는지에 초점이 맞춰 있습니다.
보통 우리가 직관적으로 하는 확률은 재현율에 가깝다고 볼 수 있습니다.
어짜피 정밀도와 재현율을 같이 쓰기 때문에 하나의 지표로 합쳐서 표시하기도 합니다.
이를 F1 점수(F1 score)라고 합니다.
F1 점수는 정밀도와 재현율의 조화 평균으로 나타냅니다.
F1=21precision+1recall=TPTP+FN+FP2
정밀도와 재현율이 비슷할수록 F1 점수가 높아집니다.
하지만 이게 무조건 좋은 건 아닙니다.
상황에 따라 달라집니다.
예를 들어, 가게의 CCTV에서 도둑을 발견하면 경비에게 알람이 울리는 분류기를 만든다고 하면 정밀도가 조금 떨어져도 괜찮지만 재현율이 아주 높아야 합니다. 조금은 잘못된 알람이 울릴 수 있긴 하지만 도둑을 거의 잡을 수 있으니까요.
반면에, 어린이를 위한 안전한 동영상만 검색하게 하는 필터 분류기의 경우는 안전한 동영상이 같이 잡히더라도 나쁜 동영상을 다 제외시키는게 중요하기 때문에 정밀도가 굉장히 높아야합니다.
그럼 정밀도와 재현율이 다 높으면 되긴 하지만 이게 불가능합니다.
이외에도 평가지표에는 정분류율(Accuracy), 오류율(Error Rate) 도 있습니다.
정분류율(Accuracy)은 전체 데이터 수에서 올바르게 분류했는지의 데이터 비율입니다.
우리가 일반적으로 말하는 정확도를 얘기합니다. 정확도는 사실 분류문제에서는 그리 중요하지 않을 때가 많습니다. 예측을 하는데 100% 정확할 수는 없다는 걸 알고 모델링을 하기 때문에 얼마나 기복없이 기계가 잘 돌아가느냐에 맞춰져 있습니다. 물론 정확도가 100%이면 가장 좋겠지만 그건 신의 영역이기 때문에 기계한테 기대할 수는 없을 것 같습니다.
정의에 따른 정분류율(Accuracy)의 식은 다음과 같습니다.
Accuracy=TP+TNTP+TN+FP+FN
오류율(Error Rate)은 정분류율의 반대입니다. 즉, 전체 데이터중 잘못 분류한 데이터수의 비율을 의미합니다.
따라서 식은 1-정분류율이 되겠습니다.
ErrorRate=FP+FNTP+TN+FP+FN
정밀도/재현율 트레이드오프
정밀도의 분모에는 FP(거짓양성) 이 들어가고 재현율의 분모에는 FN(거짓음성) 이 들어갑니다.
경사하강법으로 분류를 하게 되는데 기준을 무엇으로 정하느냐에 따라 양성으로 갈수도 있고 음성으로 갈 수도 있습니다.
모두 양성으로 분류를 해버린다면 정밀도의 분모는 커져 정밀도는 낮아지나 재현율은 높아지게 됩니다.
반대로는 재현율이 낮아지고 정밀도가 켜지는 상황이 됩니다.
이전 포스팅에서 그린 그림을 보면 정밀도와 재현율이 반대로 움직이는 걸 볼 수 있습니다.
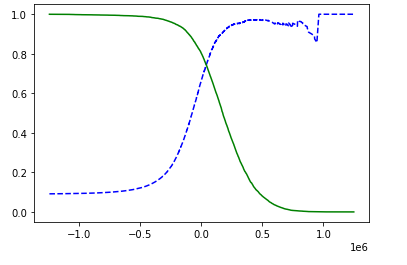
그렇기 때문에 적당한 정밀도와 재현율을 정해 분류기를 만드는게 중요합니다.
ROC, AUC
모델 비교를 위해 ROC, AUC 지표를 이용합니다.
수신기 조작특성(ROC) 곡선은 거짓양성비율(FPR) 에 대한 재현율(진짜양성비율)의 곡선입니다.
즉, 양성으로 분류되어야 하는 값을 음성으로 분류된 비율로 재현율은 분모가 TP+FN 이었다면 FPR은 FP+TN 으로 반대로 구성이 됩니다.
또한, 1- 진짜 음성 비율(TNR) 이 됩니다. TNR을 특이도(specificity) 라고도 합니다.
FPR=FPFP+TN=FP+TN−TNFP+TN=1−TNFP+TN=1−TNR
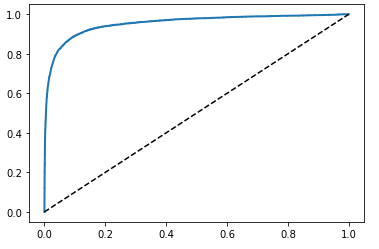
위와 같은 그림처럼 나옵니다. 파란색 곡선이 ROC인데 ROC가 점선(y=x) 에서 멀어질수록 좋은 분류기입니다.
이를 수치로 측정하는 것이 곡선아래의 면적(AUC) 입니다. 파란 곡선 아래의 면적을 구하면 수치로 나오고 1에 가까울수록 완벽한 분류기가 됩니다. 랜덤 분류기를 원한다면 0.5에 가까운 것이 더 성능이 좋은 것이 될겁니다.
AUC를 측정해 어느 기계가 더 나은 성과를 가져오는지 문제에 더 적합한 모델은 어느것인지 수치로써 다른 모델과 비교를 할 수 있습니다.
정리
혼행렬을 이용한 성능검증 개념을 살짝 알아보았습니다.
앞서 얘기한 이진분류기를 바탕으로 예를 하였고 핸즈온 머신러닝 책을 참고하였습니다.
관련 포스팅
'데이터 사이언스 > 머신러닝 딮러닝' 카테고리의 다른 글
| 선형회귀(Linear regression) (0) | 2021.12.20 |
|---|---|
| [머신러닝] MNIST를 이용한 다중분류기 구현기 (0) | 2021.12.11 |
| [분류문제] MNIST로 이진분류기 만들기 (0) | 2021.11.28 |
| [Python]회귀(3D plot) (0) | 2021.11.03 |
| [Python] 회귀(Regression) (0) | 2021.10.30 |



